一些稍微新一点或者之前没看到的想法还不错的协同感知论文
More Robust
提升检测精度,尤其是在位置噪声较大的情况下
Self-Localized Collaborative Perception
摘要
协作感知因其能够解决单智能体感知中的几个固有挑战(包括遮挡和超出范围问题)而受到广泛关注。然而,现有的协作感知系统严重依赖精确的定位系统来在智能体之间建立一致的空间坐标系。这种依赖使它们容易受到大型姿势错误或恶意攻击的影响,从而导致感知性能大幅降低。
为了解决这个问题,提出了 CoBEVGlue,这是一种新颖的自定位协作感知系统,无需使用外部定位系统即可实现更全面、更稳健的协作。CoBEVGlue 的核心是一个新颖的空间对齐模块,它通过有效匹配跨智能体的共可见对象来提供智能体之间的相对姿态。我们在真实数据集和模拟数据集上验证了我们的方法。
结果表明,i) CoBEVGlue 在任意定位噪声和攻击下实现了最先进的检测性能;ii) 空间对齐模块可以与大多数以前的方法无缝集成,将它们的性能平均提高 57.7%
介绍
准确的感知对于自动驾驶汽车的导航和安全至关重要 。尽管大规模数据集 和强大的模型 推动了进步,但单智能体感知本身受到遮挡和远程问题 的限制,这可能导致灾难性的后果。利用现代通信技术,目前对协作感知的研究使多个智能体之间能够共享感知信息,从根本上提高了感知性能。
在高质量数据集和创新协作技术的推动下,协作感知系统有可能显著提高交通网络的安全性
在这个新兴的协作感知领域,大多数主流工作都做出了一个过于简化的假设:每个代理使用的全局定位系统(通常是 GPS 或 SLAM)足够精确,可以建立一个一致的协作空间坐标系
然而,来自真实世界协作感知数据集V2V4Real和DAIR-V2X 的快照显示,即使经过细致和资源密集型的离线校准,地面实况定位仍然存在噪声。在计算限制和实时约束下,这些不准确之处在实际应用中可能会更加严重。
此外,定位系统容易受到长期存在但仍未解决的攻击。这些攻击允许攻击者随意操纵位置,进一步破坏定位系统的可靠性。这种显著噪声和恶意攻击的普遍挑战与早期工作所考虑的理想场景形成鲜明对比,这些工作主要关注轻微的姿态不准确,未能超越大噪声下无协作的基线.
为了消除对可能不可靠的外部定位系统的依赖,一种直接的解决方案是通过点云配准推断协作智能体的相对姿态,这种技术在多智能体协作系统中得到广泛应用。点云配准方法应用最近邻算法来识别广泛的3D点集之间的对应关系,然后是稳健的技术来计算这些假定对应关系的转换。尽管这些方法被证明对协作映射等延迟容忍应用有效,但对于带宽受限的协作感知系统来说,大量3D数据的实时传输是不切实际的。因此,在创建一个没有定位错误的系统,同时保持实际应用的通信效率方面,存在明显的差距。
为了填补这一空白,提出了 CoBEVGlue,这是一种自定位的协作感知系统,专为多个智能体设计,无需依赖外部定位系统即可实现更全面的感知,从而在降低通信成本的同时实现效率。CoBEVGlue 遵循以前的协作感知系统 的管道,并使用其关键的空间对齐模块 BEVGlue 来估计智能体与每个智能体检测和跟踪的物体之间的相对姿态。
BEVGlue 背后的核心思想是从跨代理的鸟瞰感知数据中搜索共见对象,并计算与这些共见对象的相对变换,确保一致的协作空间坐标系。(The core idea behind BEVGlue is to search for the co-visible objects from the bird’s eye view perceptual data across agents and calculate the relative transformation with these co-visible objects, ensuring a consistent spatial coordinate system for collaboration.)确保一致的空间坐标系以进行协作。BEVGlue 包括三个关键组件:i) 对象图建模(object graph modeling),将每个智能体的观察结果转换为具有丰富信息的对象图,包括对象形状、航向、跟踪 ID 和对象之间不变的空间关系;ii) 时间一致的最大子图检测,它有效地利用对象图中的空间和时间数据来检测最大的公共子图,遵循严格的空间同构约束和时间一致性;iii) 相对姿态计算,它使用检测到的公共子图计算代理之间的姿态关系,而无需使用耗时的异常值拒绝算法。
拟议的 CoBEVGlue 系统具有三个显着优势:
i) 它独立于外部定位设备运行,展示了其对噪音和恶意攻击的弹性
ii) 它带来的通信开销很小,因为 CoBEVGlue 仅使用带有跟踪 ID 的对象边界框来估计代理之间的相对姿势
;iii) 其核心模块 BEVGlue 通过在检测到的公共子图之间保持严格的空间同构约束和匹配结果之间随时间的时间一致性来确保高质量的匹配结果。
为了评估所提出的方法的有效性,考虑了三个数据集上的协作式3D目标检测任务:OPV2V、DAIR-V2X和V2V4Real,涵盖模拟和真实世界场景。结果表明,CoBEVGlue 赋予了强大的协作感知系统的性能与依赖精确定位信息的系统相当,并在存在定位噪声和攻击时实现了最先进的检测性能
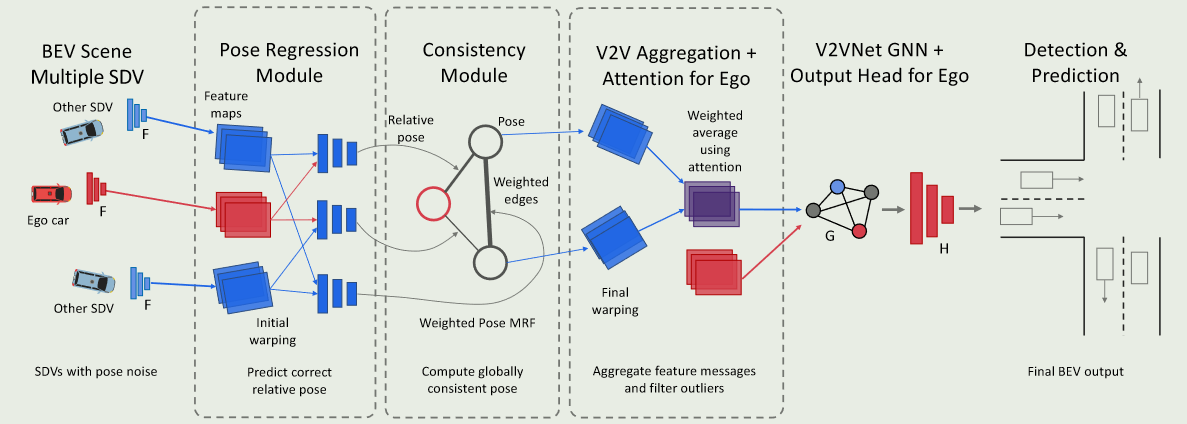
为了获得对定位噪声的抵抗力,以前的工作考虑了两种主要方法:基于学习和基于匹配。基于学习的方法旨在构建健壮的网络架构,以减少姿态错误的影响。例如,V2VNet(稳健性) 设计了姿态回归、全局一致性和注意力聚合模块来纠正相对姿态并专注于姿态误差较小的邻居;V2X-ViT 使用多尺度窗口注意力来捕获各种范围内的特征。另一方面,基于匹配的方法寻求开发健壮的框架或网络架构。示例包括 FPV-RCNN和 CoAlign,它们使用基于 IoU 的匹配策略估计代理之间的相对姿势。但是,它们只能纠正外部定位中的微小不准确之处,因为这些方法依赖于基本精确的初始相对姿势。当噪声较大或存在攻击时,它们的性能会显著下降。相比之下,我们的工作认为协作感知独立于外部定位系统
尽管本文的最终目标是提高检测能力,但点云配准方法的进步激发了我们提出新颖的自定位协作感知系统。传统的点云配准方法专注于改进迭代最近点 (ICP) 算法及其变体 导致了收敛和噪声弹性的改进。最近典型的点云配准工作流程包括提取本地 3D 特征描述符和进行配准。为了提取 3D 局部描述符,快速点特征直方图等传统方法利用了手工制作的特征。
最近的技术为此目的采用了基于学习的方法。在配准方面,传统方法通常采用最近邻算法进行匹配,并采用稳健优化来剔除异常值,而现代深度配准方法则利用自注意机制来确定对应关系。SGAligner率先使用预构建的 3D 场景图进行配准。然而,与前面的策略类似,它需要传输密集的点云和高维特征。这些方法广泛应用于容忍延迟的多智能体系统,如协同映射和 3D 场景图生成.但是,协作对象检测任务需要实时进行精确的相对姿态估计。遗憾的是,V2X 网络难以实时传输点云配准方法所需的密集点云和特征。为了克服这一限制,我们的方法优先考虑对象级注册,仅用 8 个 float 数字表示每个对象(To overcome this limitation, our approach prioritizes object-level registration, representing each object with just eight float numbers.)。这项创新显著降低了计算协作自动驾驶汽车之间相对姿态所需的带宽和计算成本,从而有效地解决了传输困境(This innovation markedly reduces the bandwidth necessary and computation cost for calculating relative poses among collaborative autonomous vehicles, thus efficiently resolving the transmission dilemma)
最大公共子图(Maximum Common Subgraph Detection,MCS)检测问题被归类为NPhard,在各个科学领域中都至关重要,需要平衡精度和计算效率的算法。传统方法主要采用分支定界算法和将 MCS 检测转化为最大团问题的技术. 机器学习的最新进展已经看到了图神经网络和强化学习在 MCS 检测中的应用,MCS 检测试图学习合适的启发式方法来进行图匹配。尽管他们进行了创新,但它们仍然受到搜索空间探索的启发式性质的限制,并且在最坏的情况下会受到指数级时间复杂度的影响。在这项工作中,我们使用几何不变对象姿态图对每个代理检测到的边界框进行建模,并利用空间约束和时间一致性来有效地解决问题。
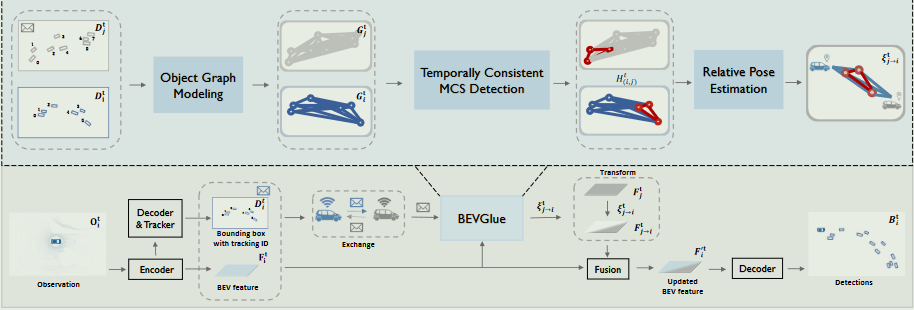
精确的姿态信息要求每个代理利用外部定位系统来获取其全局位置并计算协作者之间的相对变换。这种对外部定位的依赖充满了挑战,包括容易受到噪声干扰和恶意攻击造成的潜在安全漏洞。BEVGlue 旨在通过利用感知数据来确保准确的相对姿态估计来解决这些问题,从而增强协作感知的弹性和有效性。
为了估计智能体之间的相对姿态 ξt j→i,BEVGlue 的主要思想是识别共可见的物体,然后根据这些共见物体计算变换。为了挖掘智能体之间的这种内部对应关系,BEVGlue 提出了三个模块:(i) 对象图建模,(ii) 时间一致的最大公共子图检测,以及 (iii) 相对姿态计算。
Object Graph Modeling
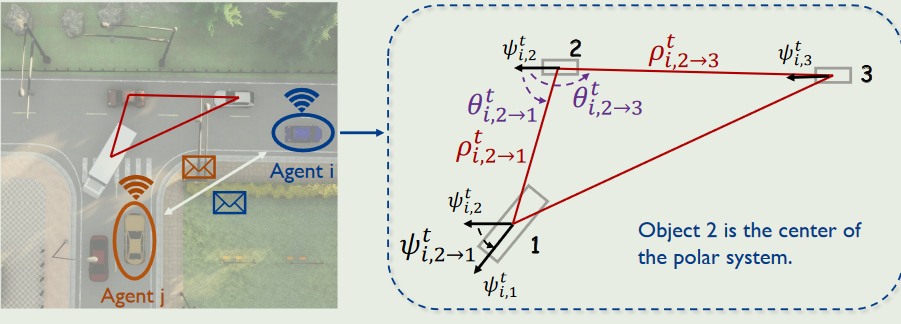
鉴于极点和参考方向在物理世界中具有清晰和单一的定义,因此可以实现不同对象图之间边缘特征计算的一致性。具体来说,如果在基于智能体 j 计算智能体图 Gt j 上的边缘特征 e^t^j,mn 时,节点 m 和 n 的检测结果对于第 i 个和第 j 个智能体都是准确的,则它与 e^t^i,mn 相同。
对象图提供了一种创新方法来对每个代理的观察进行建模:i) 节点属性包含时间跟踪数据,这有助于保持随时间推移的匹配一致性;ii) 边缘特征在从不同代理的角度得出的对象图中是一致的,这意味着应用于 D^t^i 的旋转和平移不会改变 e^t^ i,mn 的值。这意味着,当两个对象同时被不同的代理观察时,无论视角如何变化,边缘属性都保持一致。
对象图提供了一种创新方法来对每个代理的观察进行建模:i) 节点属性包含时间跟踪数据,这有助于保持随时间推移的匹配一致性;ii) 边缘特征在从不同代理的角度得出的对象图中是一致的,这意味着应用于 D^t^i 的旋转和平移不会改变 e^t^i,mn 的值。这意味着,当两个对象同时被不同的代理观察时,无论视角如何变化,边缘属性都保持一致
每个代理根据自己的检测结构建模一个对象图,图中有一些节点和边.
每个节点属性包括bbox的宽高和id,边节点属性包括相对距离,相对航向角和航向角相对
上面的MCS函数可以分为三个过程.具体我就不说了,这篇文章一般,在一些介绍上还有点含糊不清.

FeaCo: Reaching Robust Feature-Level Consensus in Noisy Pose Conditions
之前说过这篇文章,核心在两个模块,一个针对位置噪声,一个使用多尺度融合提升精度.
我想说的就是其中的针对噪声的小模块.
Pose-error Rectification Module
使用这种类型模块的根本原因是我们得到的除了ego车辆的位置,collborator的位置很可能有误差.

如果直接使用粗变换的特征图进行推理,可能会出现来自不同CAV的分歧。因此引入了姿态误差校正模块( PRM ),以保持在噪声条件下的鲁棒性
可以分为两个阶段,定位阶段推导出空间置信图,有助于选择特征级的候选匹配区域。匹配阶段得到细粒度的变换矩阵,并导出对齐的特征图。(目的是在使得来自不同车辆经过转换后的特征达到匹配)
Proposal Regions Localization.由于视角的重叠,在感知过程中,同一目标可以被多个AV检测并存储在它们的特征级表示中。因此,对特征图上的目标位置和关系进行建模变得尤为重要。理性建模可以更好地定位候选匹配区域,从而获得精确的变换矩阵
使用空间置信图作为包含语义信息的置信水平的表示。它由检测头从Φ Enc提取的特征中生成,反映了不同空间区域的感知关键程度。具体来说,感知临界水平高的区域表示潜在的匹配区域,而较低的区域通常表示冗余背景
二值感知图是通过极大值选择得到的,其中取值为1的像素表示建议像素,取值为0的像素表示背景。
为了进行特征级匹配,需要收集像素级的局部信息作为区域级的表示。因此将每个连通矩形区域的中心作为候选匹配区域的代表。将ego AV得到的中心点集合记为P,将噪声姿态条件下CAV得到的中心点集合记为Q
Proposal Centers Matching.为了获得细粒度的变换矩阵,需要对不同集合中的导出建议中心进行匹配。对于集合P中的每个点,目标是在集合Q中分配一个唯一的检测框。然而,一些建议匹配区域可能由于视觉遮挡和距离而无法匹配,因此关键是找到一种有效的策略,在具有不均匀匹配和高位姿噪声的对齐特征图中达成鲁棒的共识.在上一步得到候选区域集合的基础上进行匹配,
将Q~k~中与自我特征中任何提议匹配区域接近的每个中心视为贡献中心,并将其包含在Q~near~中。类似地将ego AV的中心集记为P~near~

接下来构建一个带权二部图G,分别使用端点来自P~near~和Q~near~。每条边的权重由两个中心之间的距离决定,记录在成本矩阵C中. 然后将匹配过程转化为G上的linear assignment任务,旨在寻找边权重之和最小的匹配方案。位姿误差会导致特征图之间的定位不准。经过赋值过程,编号为1和2的自我特征图中的提议中心分别成功匹配到CAVk的中心1′和2′。
其中主要涉及到linear_assignmentlinear_sum_assignment — SciPy v1.14.1 Manual和MADMean Absolute Deviation: Definition, Finding & Formula - Statistics By Jim,Mean Absolute Deviation (MAD): What It Means and Formula | Outlier相对传统的算法,最后通过一个损失函数优化位置转换矩阵
上面整个过程我最不能理解的就是MAD结果得到了M~p~和M~q~两个值,
ERMVP: Communication-Efficient and Collaboration-Robust Multi-Vehicle Perception in Challenging Environments
Filter and Merge Feature Sampling
使用了Filter and Merge Feature Sampling用于压缩,它包含若干个部分. 首先使用一个常用的置信度generator,得到特征的置信度,选择一个阈值得到一个binary mask在0-1之间,再使用这个mask得到相当于过滤后的特征. 论文将特征图当作了一个feature vector set,使用KNN(原文说的是variant of the nearest neighbor)聚类,然后给再用另一种指标给这些feature vector找类别.
假设分了G个类别,针对每个类别,计算属于这个类别的特征的某种均值. 其中c就是之前求的置信度.
这就相当于进行了压缩,传递的时候只需要传递G个vector和filter sampler之后特征的index方便重建.
Feature Spatial Calibration
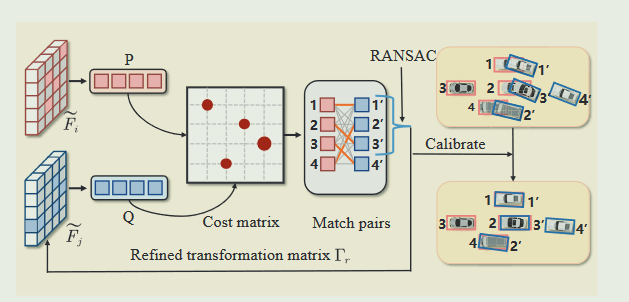
解决位置噪声提高鲁棒性. 当ego车拿到其他collborator的特征并重构之后,将ego车辆的建议匹配区域记为P,协作车辆在噪声位姿条件下识别的匹配区域记为Q。利用P和Q,构造了一个加权二部图,其中每条边的权重由节点之间的距离确定,并封装在一个成本矩阵中(说实话,跟Feaco挺像的),然后,将匹配过程转化为线性分配任务,目标是识别具有最低累积边权重的匹配结果。这个过程产生了匹配对M,然后使用了一种叫做RANSAC(我没用过)的算法,相当于随机找M的子集,使用SVD(奇异值分解)得到转换矩阵,使得转换这个子集中的collborator特征与ego特征的(通过检测网络得到的匹配区域的)距离小于一个阈值即可.这个过程是迭代进行的,以确定与最大正确匹配数相关的最佳变换矩阵。目的就是求的一个更好的位置转换矩阵,使得转换后的特征与ego的特征通过检测网络得到的bbox(我猜测是通过检测网络后的连通区域的中心)距离最小. 最后还有个所谓的error modulation,看起来就是把转换后的特征与之前的特征与ego特征(感觉原文说的不太明白,更像是proposed matching regions的重叠区域)的重叠区域谁更大,取更大的对应的特征.
剩下的就是特征融合模块了,经典的各种attention,不用多讲.
这篇文章虽然是CVPR,但真的…挺一般,代码也写得很差…感觉像是一篇可能还行的缝合怪,我能看到的缝合痕迹就有where2comm,Feaco,SCOPE.
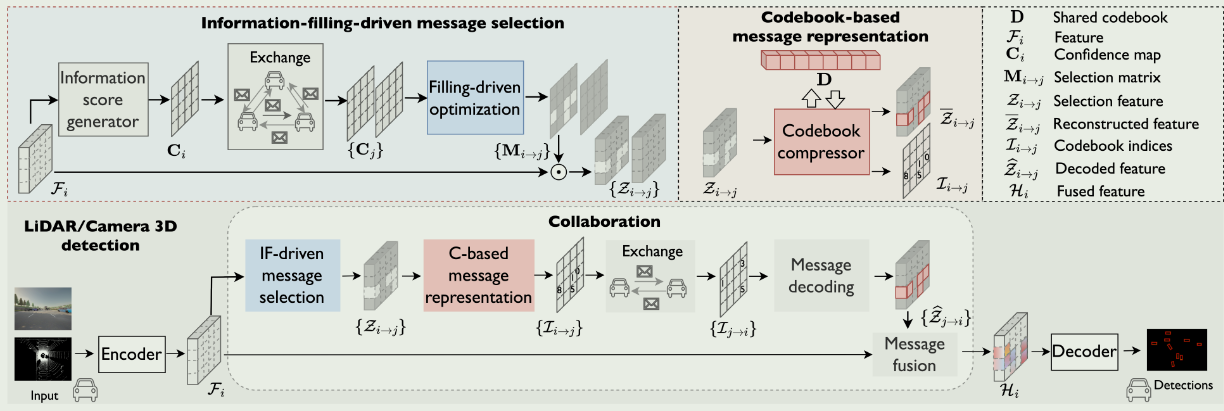
Communication-Efficient Collaborative Perception via Information Filling with Codebook
Information-filling-driven message selection
Φ generator ( · )由检测解码器实现。当生成信息得分图时,每个智能体将其广播给其他智能体。这种初始通信是高效的,因为轻量级的信息得分图.(还是where2comm中的东西)
Codebook-based message representation
为了有效地传输所选择的特征映射Zi→j,每个代理使用一种新的基于码本的消息表示,从而降低了沿信道维度的通信成本。其核心思想是从任务驱动的码本中用最相关的码来近似一个高维的特征向量;因此,只需要传输整数代码索引,而不需要传输由浮点数组成的完整特征向量。

Message decoding and fusion
消息解码根据接收到的码本索引和共享码本重构supporter的特征
给定接收到的消息P~j→i~ = I~j→i~,解码特征图位于(h,w)处的Z~j→i~∈R^H×W×C^元素为( Z~j→i~ )~[h,w]~ = D[ I~j→i~ [ h , w] ]
随后,信息融合将解码后的特征图进行聚合以增强个体特征,通过non-parametric point-wise maximum fusion.
这也是cvpr,也挺烂的… 怎么感觉cvpr越来越水了…
新颖点在于使用vqvae中提出的codebook,印象里应该是这个方向中第一篇使用codebook,共享index的文章
Learning to Communicate and Correct Pose Errors
Robust Collaborative 3D Object Detection in Presence of Pose Errors
ParCon: Noise-Robust Collaborative Perception via Multi-Module Parallel Connection

More domain-invariant
提升迁移性,在仿真数据集上训练能在真实数据集上保证良好的效果.
V2X-DGW: Domain Generalization for Multi-agent Perception under Adverse Weather Conditions
当前基于激光雷达的V2X ( Vehicle-to- Everything )多智能体感知系统在三维目标检测方面取得了显著的成功。虽然这些模型在训练好的清洁天气中表现良好,但它们在未见到的不利天气条件下与真实世界的域差距进行了斗争。在本文中提出了一种在恶劣天气条件下基于多智能体感知系统的激光雷达三维目标检测的领域泛化方法,命名为V2X - DGW。我们的研究不仅在干净的天气下确保良好的多智能体性能,而且在未见到的恶劣天气条件下,只对干净的天气数据进行学习
为了推进该领域的研究,我们模拟了三种常见的不利天气条件对两个广泛使用的多智能体数据集的影响,从而创建了两个新的基准数据集:OPV2V-w和V2XSet-w。为此,我们首先引入自适应天气增强( AWA )来模拟不可观测的不利天气条件,然后提出两种用于泛化表示学习的对齐方式:信赖域天气不变对齐( TWA )和Agent感知对比对齐( ACA )。大量的实验结果表明,我们的V2X - DGW在看不见的恶劣天气条件下取得了改善。
DUSA
车联网( Vehicle-to-Ething,V2X )协同感知对于自动驾驶的推进至关重要。然而,实现高精度的V2X感知需要大量有标注的真实世界数据,这些数据通常是昂贵和难以获得的。由于模拟数据可以以极低的成本大规模生产,因此受到了广泛的关注
然而,模拟数据与真实世界数据之间显著的域差距,包括传感器类型、反射模式和道路环境的差异,往往导致在模拟数据上训练的模型在真实世界数据上评估时性能较差。此外,现实世界中的协作智能体之间仍然存在着域间鸿沟,例如,不同类型的传感器可能安装在具有不同外在特征的自动驾驶车辆和路边基础设施上,进一步增加了sim2现实泛化的难度

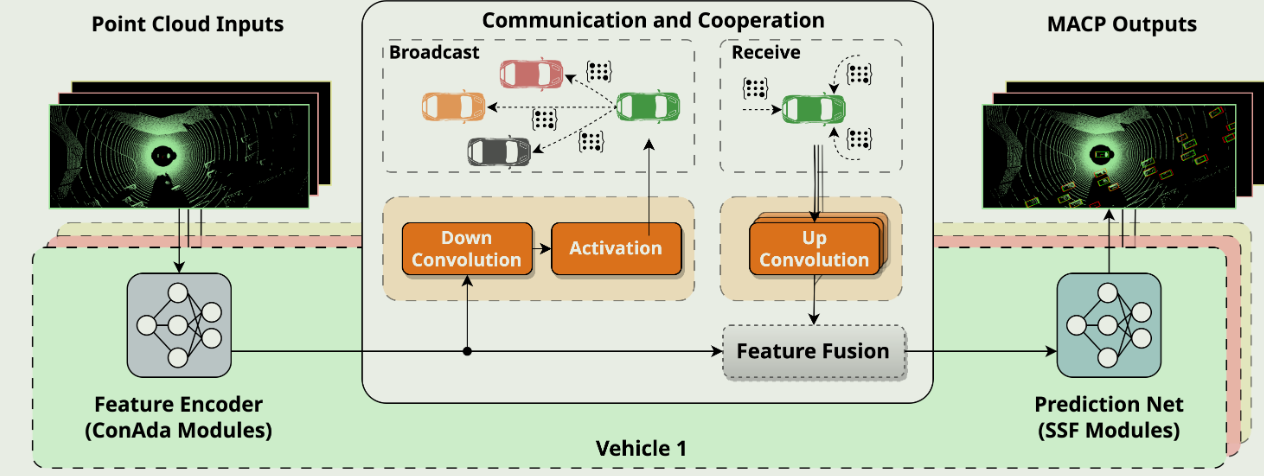
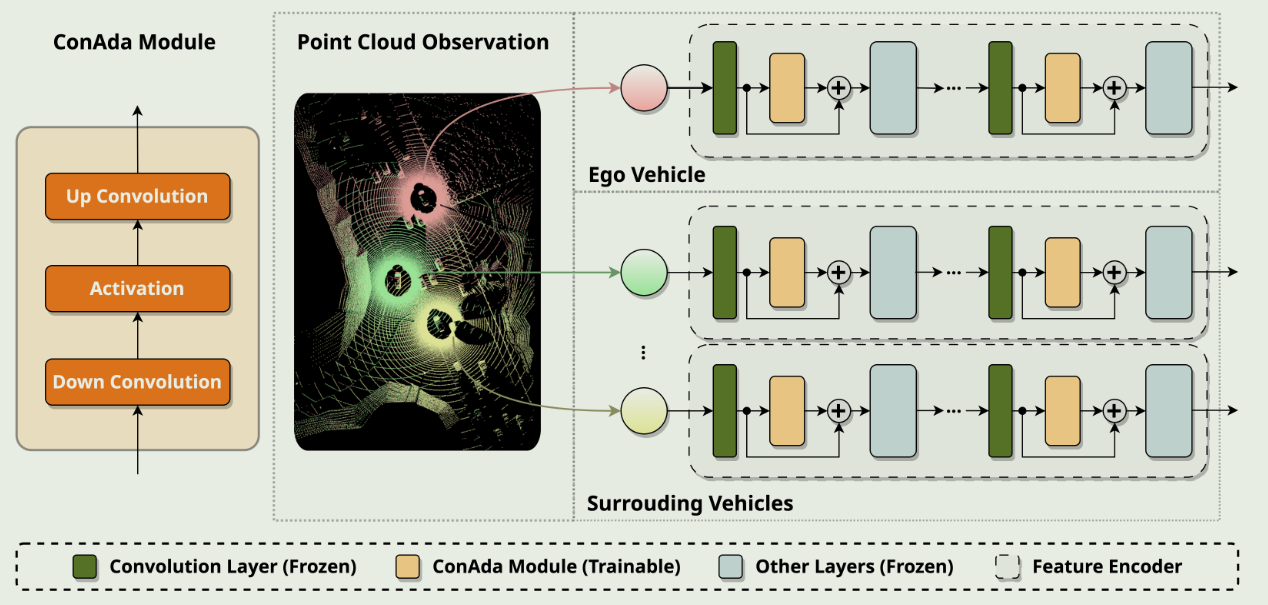
MACP
车车通信( V2V )通信通过使信息共享能够”看穿遮挡物”,极大地增强了联网和自动驾驶汽车( CAV )的感知能力,从而带来了显著的性能提升。然而,当现有的单智能体模型表现出显著的泛化能力时,从头开始开发和训练复杂的多智能体感知模型可能是昂贵的和不必要的。在本文中,我们提出了一个新的框架MACP,它配备了一个具有合作能力的单智能体预训练模型。我们通过确定从单Agent转移到合作设置的关键挑战来实现这一目标,通过冻结其大部分参数和增加一些轻量级模块来调整模型。我们在实验中证明了所提出的框架可以有效地利用合作观测,并且在模拟和真实世界的合作感知基准中优于其他最先进的方法,同时需要更少的可调参数,并减少通信成本。
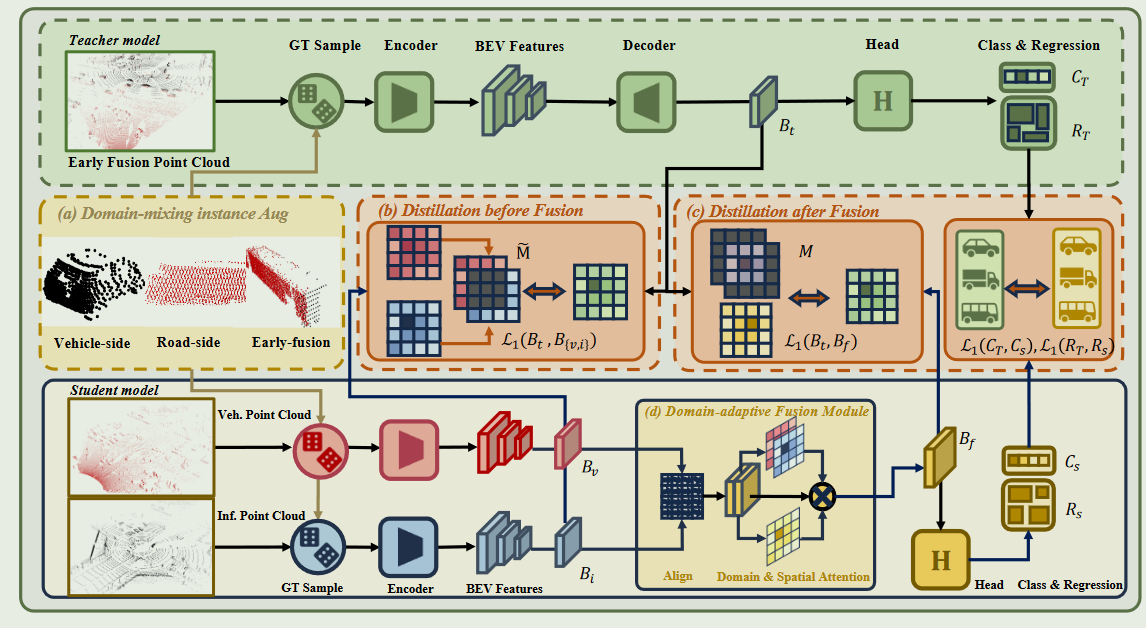
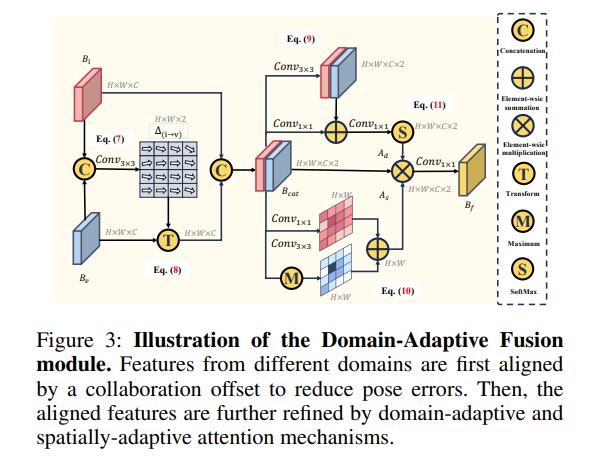
DI-V2X
近年来,车联网( Vehicle-to- Everything,V2X )协同感知技术因其能够融合车辆、基础设施等多种智能体的信息来增强场景理解而受到广泛关注。然而,目前的工作往往将每个智能体的信息同等对待,忽略了由于每个智能体使用不同的LiDAR传感器而导致的固有域间隙,从而导致次优的性能。
在本文中,我们提出了DI - V2X,旨在通过一个新的蒸馏框架来学习领域不变的表示,以减轻V2X 3D目标检测中的领域差异。DI - V2X包括3个核心组件:域混合实例增强( DMA )模块、递进域不变蒸馏( PDD )模块和域自适应融合( DAF )模块。具体来说,DMA在训练过程中为教师和学生模型建立一个领域混合的3D实例库,从而产生对齐的数据表示。其次,PDD鼓励来自不同领域的学生模型逐步学习面向教师的领域不变特征表示,其中智能体之间的重叠区域被用作指导,以促进蒸馏过程
此外,DAF通过引入校准感知的领域自适应注意力来缩小学生之间的领域差距。在具有挑战性的DAIR - V2X和V2XSet基准数据集上的大量实验表明,DI-V2X取得了显著的性能,超过了之前所有的V2X模型。
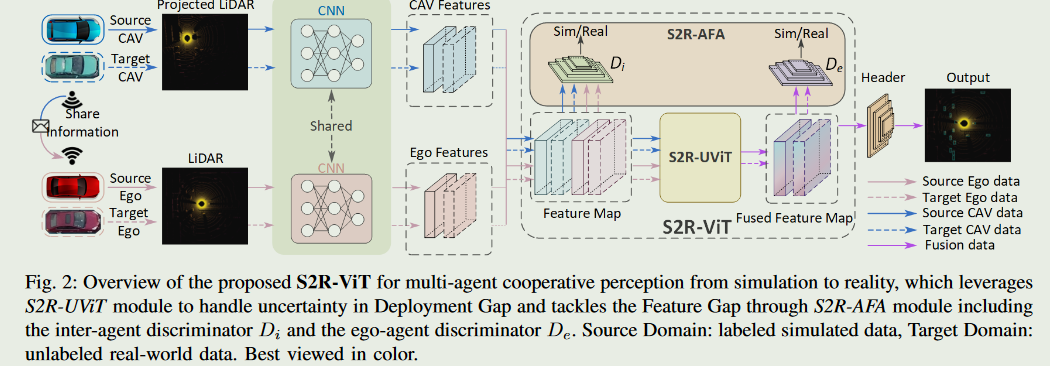
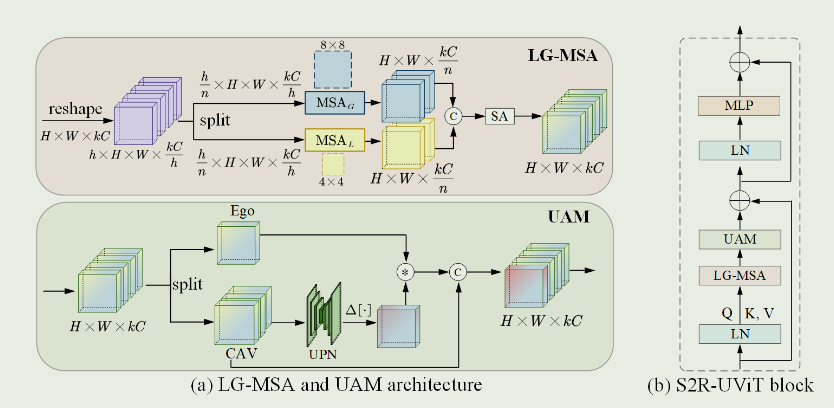
SR2ViT
由于缺乏足够的真实多智能体数据且标注耗时,现有的多智能体协同感知算法通常选择模拟的传感器数据进行训练和验证。然而,当这些经过仿真训练的模型被部署到真实世界时,由于仿真数据和真实数据之间存在显著的领域差距,感知性能会下降。在本文中,我们提出了第一个使用新型视觉转换器的多智能体协作感知的仿真到现实迁移学习框架,命名为S2R - ViT,它同时考虑了模拟数据和真实数据之间的部署差距和特征差距。
我们研究了这两种类型的域间隙的影响,并提出了一种新的不确定感知视觉转换器来有效地缓解部署间隙,并提出了一种基于代理的特征自适应模块,通过代理间和代理内的鉴别器来减小特征间隙。在公开的多智能体协同感知数据集OPV2V和V2V4Real上的大量实验表明,本文提出的S2R-ViT方法能够有效地弥补仿真与现实之间的差距,在基于点云的三维目标检测中显著优于其他方法。
TransIFF: An Instance-Level Feature Fusion Framework for Vehicle-Infrastructure Cooperative 3D Detection with Transformers
More Communication-efficient
减少传输的数据大小,使得通信更高效.
ERMVP: Communication-Efficient and Collaboration-Robust Multi-Vehicle Perception in Challenging Environments
协作感知通过使自动驾驶汽车能够交换互补信息来提高感知性能。尽管它有可能彻底改变移动行业,但各种环境中的挑战,如通信带宽限制、定位错误和信息聚合效率低下,阻碍了它在实际应用中的实施。在这项工作中,我们提出了 ERMVP,这是一种在具有挑战性的环境中进行通信高效和协作的鲁棒多车辆感知方法。具体来说,ERMVP 具有三个明显的优势i) 它利用分层特征采样策略来抽象一组具有代表性的特征向量,使用更少的通信开销实现高效通信;ii) 它采用稀疏一致性特征来执行精确的空间位置校准,有效减轻车辆定位错误的影响;iii) 引入了一种开创性的特征融合和交互范式,以在不同车辆和数据源之间集成整体空间语义。
自动驾驶汽车被广泛认为是提高道路安全和交通效率的重要手段。这些车辆配备了激光雷达、摄像头和其他传感器,能够准确感知周围环境,以确保安全可靠的运行。然而,单车感知系统不可避免地存在缺点 ,例如传感器视野有限,容易被遮挡,以及由于数据稀疏和低分辨率而难以检测远处物体。
最近,车对车 (V2V) 通信技术和深度学习的进步刺激了协作感知技术的创新和进步。这项技术允许互联自动驾驶汽车 (CAV) 共享传感数据,从而实现更全面的环境感知.
尽管协作感知技术在移动出行行业转型方面显示出巨大潜力,但其实际应用面临一些挑战,包括通信带宽限制、定位错误和信息聚合效率低下
在实际场景中,无线通信资源和可靠性的约束严重阻碍了延迟敏感协作感知的有效性。虽然最近的工作通过精心设计的机制实现了感知性能和通信带宽之间的平衡,但这些方法有其局限性,因为它们主要考虑信息压缩而不是空间冗余。这种狭窄的关注点会加剧高压缩比下的性能下降.
此外,复杂的动态环境会导致定位错误,从而导致相对变换估计不准确和空间特征错位。这种相对姿势噪声会产生误导性特征,从而对协作感知的有效性产生不利影响。现有的方法试图通过密集的计算来优化整体姿态,但高延迟使其不适合实时动态感知.同时,协作方法只关注聚合信息,而忽视了自我载体固有的感知优势.此范例容易受到协作噪声引入的扰动的影响,包括异步运动模糊和不准确的投影.这样的缺点成为实现最佳感知性能的瓶颈.
相比之下,以自我为中心的特征可能包含不受协作噪声影响的局部准确空间位置信息。因此,建立务实的协作感知系统的首要任务是有效克服上述挑战.

基于这些观察提出了 ERMVP,这是一种在具有挑战性的环境中通信高效且协作稳健的多车辆感知方法。具体来说,(i) 首先设计了一种高级滤波器和合并特征采样策略来解决无线通信资源的局限性。此策略同时考虑类间和类内冗余关系,以从冗余特征中抽象出一组精炼的特征向量,从而使用更少的通信开销实现高效通信.(ii)其次,我们引入了一个即插即用功能空间校准模块,以减轻车辆定位错误的影响。该模块巧妙地利用共识稀疏前景特征来对齐自我车辆和合作者之间的相对姿态关系,而无需任何精确的姿态监督。(iii)此外提出了一种开创性的特征融合和交互范式,以整合整体空间语义。
该范式包括两个关键组件:第一个是基于注意力的特征融合模块,在本地和全局注意力之间交替,以融合来自不同车辆的异构信息.
第二种是准确性增强特征交互策略,它利用以自我为中心的特征中固有的准确位置信息来增强融合特征提供的丰富语义信息.
• 我们提出了 ERMVP,这是一种通信高效且协作稳健的多车辆感知方法,它解决了通信带宽限制、定位错误和信息聚合效率挑战。
• 我们开发了一个过滤和合并特征采样策略来提高通信效率,一个用于精确空间特征对齐的特征空间校准模块,以及两个信息聚合组件来优化融合过程。
• 我们对真实世界和模拟数据集进行了广泛的实验。结果表明了我们方法的优越性和所提出组件的必要性。
Filter and Merge Feature Sampling
以前的工作利用了精心设计的机制,如信息熵通信选择 [37] 和空间异质性映射来减少所需的传输带宽。
然而,这些方法主要关注前台和后台特征之间的类间冗余,而忽略了特征之间的类内冗余,从而导致次优压缩。为了解决这一差距,我们引入了一种高级过滤和合并特征采样策略 (FMS)。该策略同时考虑了类间和类内冗余关系,有效地从原始特征图中提取了一组简洁而独特的特征向量,从而更有效地减少了通信开销。FMS 由以下两个核心组件组成。
Filter Sampler(滤波器采样器).在对象检测中,包含对象的前景区域比背景区域更重要。因此,我们将减少空间冗余的想法实现到特征过滤器采样器模块中,旨在保留感知上重要但稀疏的特征向量集。由于显式学习二进制采样器是不可行的,因此我们开发了一种置信度过滤器策略.最初,为特征图生成检测置信度图。它反映了不同空间区域的感知重要性,较高的级别表示潜在的对象区域,较低的级别通常表示冗余的背景区域.
其中 Φcon_gen(·) 表示具有检测解码器结构的置信度生成网络。然后对置信度图进行阈值处理,然后进行非极大值抑制,从而产生二进制掩码 B。
Merge Sampler(合并采样器):在用滤波器采样器提取详细的前景特征向量集后,我们使用合并采样器进行额外的优化,通过加权合并来提炼相似或重复的前景特征向量。该过程分为三个阶段:信息驱动的特征分组、注意力启发的特征合并和基于索引的特征重建(information-driven feature grouping, attention-inspired feature merging, and index-based feature reconstruction.)
应用最近邻聚类算法的变体对前景特征向量集进行分组.给定一组特征向量 $F^{~}_{i}$ =[x1,x2,…,xL] 和集群中心 $X_c$,我们计算每个特征向量的指标 δi。
δi 的计算方法是最小特征距离减去到任何其他聚类中心向量的平均像素距离
- 合并特征向量的一种简单策略是平均集群中的每个特征向量。但是,此方案可能会受到异常值特征向量的严重影响。从注意力机制中汲取灵感,利用置信度分数作为指导来量化每个特征的重要性。因此,第 i 个簇 Gi 的合并特征向量 ̃ 习 计算为
- 在特征分组和合并过程中,每个特征向量都分配给一个集群,每个集群由一个合并的向量表示。维护原始特征向量和合并特征向量之间的索引对应关系的记录。利用这个索引记录,自我车辆确保合并的特征向量被映射到它们的相应位置,从而重建特征图
定位错误可能导致车辆之间的特征图错位。这种错位会导致自我车辆误解物体的位置,从而导致感知能力下降,为了应对这一挑战,引入了特征空间校准模块 (FSC) 来促进精确的特征对齐

涉及三个阶段:一致性匹配、几何验证和误差调制。
将自我车辆的拟议匹配区域表示为 P,将协作车辆在嘈杂姿势条件下识别的区域表示为 Q。利用 P 和 Q,构建了一个加权二分图,其中每条边的权重由节点之间的距离决定,封装在成本矩阵中。然后将匹配过程转换为线性分配任务,目的是确定具有最低累积边缘权重的匹配结果。此过程将生成匹配的对 M
由于对象位于专用区域和检测噪声,可能会出现无效匹配。为了解决这个问题,我们利用 RANSAC 来过滤和筛选一组与预期几何变换一致的匹配项。首先,选择一个随机匹配子集Ms ,然后利用奇异值分解计算变换矩阵Γ s .当Γ s应用于Ms内的所有对时,如果这些对之间的变换后距离保持在阈值η以下,则认为该集合是正确对齐的。阈值η反映了原始协作框架内允许的定位误差。这个过程是迭代进行的,以确定与最大正确匹配数相关的最佳变换矩阵。最终得到一个最优的精化变换矩阵Γ r,并将其应用于后续的空间标定操作中,得到对齐后的特征’ Zj = Γ rZj
为了增强校准方法在各种环境下的适应性,我们融入了误差调制策略。该策略旨在实现定位误差与标定过程中产生的估计误差之间的平衡。它测量了自我和协作特征在调整状态和原始状态下的重叠比例。
Attention-based Feature Fusion
在多车辆协作场景中,车辆能够捕获来自不同空间区域的异构信息。为了高效地融合来自多个车辆的感知特征,我们提出了一种注意力特征融合方法( AFF )。AFF利用交替的局部和全局注意力,在遮挡变化的交通场景中实现位置级别的精确匹配,并捕获道路拓扑和交通状态的全局语义注意力

该模块允许系统从局部视图分析空间相关性,同时也捕获全局特征响应,确保在动态、复杂和遮挡变化的交通场景中实现高效和精确的感知.最后得到融合特征H~i~
Accuracy Enhanced Feature Interaction
先前的工作已经证明了融合特征可以提供更丰富的语义信息,从而提高感知性能。然而,它们可能会受到协作噪声的影响,如异步运动模糊和不准确的投影,这会损害准确的位置信息,成为感知性能最优实现的瓶颈.以自我为中心的特征可能包含局部关键的空间位置信息,而不受协作噪声的影响.
为此,我们提出了一种准确性增强的特征交互( Accuracy Enhanced Feature Interaction,AEI )策略,该策略利用自我中心特征固有的准确位置信息来增强协同融合特征提供的丰富语义信息.

Pragmatic Communication in Multi-Agent Collaborative Perception
多智能体协同感知的目标是使智能体通过通信交换互补的感知信息,从而实现更全面的感知。协同感知保证了扩展的可视性,通过障碍物和识别小的、远距离的目标,从而实现对环境的彻底理解。它为从根本上克服单智能体感知的物理局限性提供了一个很有前途的方向,如视场受限、遮挡、远距离等问题。作为自主系统的最前沿,协作感知可以增强感知能力,并在各种现实世界的应用中进一步提高系统的功能和安全性,包括自动驾驶机器人技术和无人驾驶.
为了应对这一挑战,关键在于在通信预算范围内优化消息以满足每个智能体的特定感知任务需求。一种直接的方法是在传统的香农通信范式中使用信源编码。该方法将原始数据编码为一系列代码,将较短的代码分配给频繁数据,将较长的代码分配给稀有数据,在不损失信息的情况下创建紧凑的表示。在协同感知的背景下,该方法在支持者端有效地将感知数据压缩为消息,并在接收者端确保无损复制.
这种方法提高了通信效率,同时保留了对包括感知在内的一般下游任务的效用。然而,这种Shannon范式在需要为特定下游任务定制通信的场景中具有根本的局限性,因为它不可避免地浪费了无关的资源数据。例如,在相机-传感器-智能体协作的车辆检测任务中,香农范式对每个像素进行统一编码,而不区分非必要的背景和关键的车辆像素。这些背景像素在无助于检测性能的情况下极大地浪费了通信资源,从而影响了感知-通信的权衡。
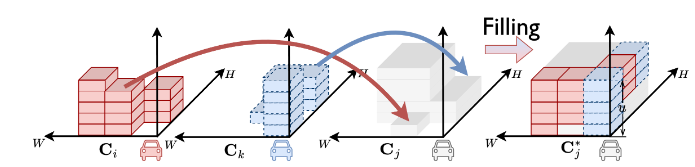
spatial confidence map+VQVAE
Information-filling-driven message selection
为了有效地选择支持其他Agent的紧凑协作消息,核心思想是使每个代理能够有限制地选择相关的消息与其他代理共享;然后,这些非冗余消息共同满足彼此的信息需求。例如,在遮挡场景中,来自支持者的额外信息有助于智能体检测丢失的物体。然而,来自多个支持者的信息被过度填充,浪费了沟通资源。因此,集体协调对于避免冗余和提供更多有益信息至关重要。为了实现这一点,提出的方法有两个关键步骤:information disclosure,其中智能体相互分享它们在特定区域的可用信息. filling-driven optimization,其中每个智能体局部优化对其他智能体的支持性信息
Codebook-based message representation
Codebook learning
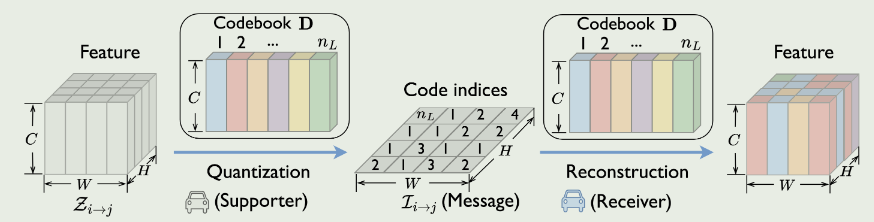
令D = [d1,d2,· · ·,d~nL~]∈R^C×nL^为codebook,其中D [l] = d~l~∈R^C^为第l个码字,nL为codebook个数。
Ψ ( · )表示用D [l]代替F[ h , w]所获得的检测性能.第一项反映了下游检测任务的要求,第二项反映了原始特征向量与编码之间的重构误差
这种近似对重构是有损的,而对感知任务是无损的,能够在不牺牲感知能力的情况下降低通信成本
Code index representation
在共享codebook D的基础上,每个智能体可以通过一系列码本索引I~i→j~来替代所选择的稀疏特征图Z~i→j~
Message decoding and fusion
消息解码根据接收到的codebook索引和共享codebook重构支持特征
给定接收到的消息P~j→i~ = I~j→i~,解码特征图位于( h , w)处的$\widehat{\mathcal{Z}}{j\to i}\in\mathbb{R}^{H\times W\times C}$元素为$(\widehat{\mathcal{Z}}{j\to i}){[h,w]}=\mathbf{D}{[\mathcal{I}{j\to i}[h,w]]}$。随后,消息融合将这些解码后的特征图进行聚合以增强个体特征,通过非参数逐点最大融合实现。对于第i个agent,给定重构特征$\widehat{z}{j\to i}$ .增强的BEV特征为$\mathcal{H}i=\max{j\in\mathcal{N}i}(\mathcal{F}_i,\widehat{\mathcal{Z}}{j\to i}) \in \mathbb{R}^{H\times W\times C}$,其中N~i~是第i个Agent的连通合作者,max ( · )最大化每个代理空间位置上来自多个Agent的相应特征
对增强后的特征H~i~进行解码得到检测结果O~i~
What Makes Good Collaborative Views? Contrastive Mutual Information Maximization for Multi-Agent Perception
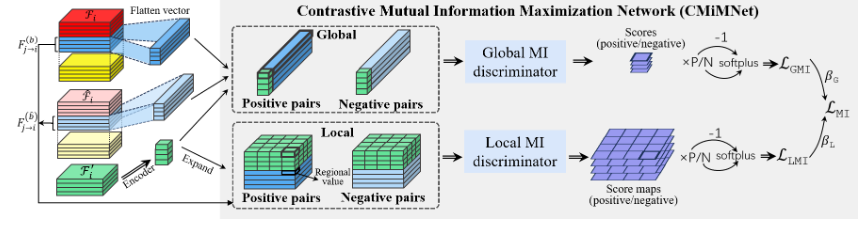
多智能体感知( Multi-agent perception,MAP )允许自主系统通过解释来自多个来源的数据来理解复杂环境。本文研究MAP的中间协作,重点探索协作视图(即,后协作特征)的”好”特性及其与单个视图(也就是说,合作前的特征)的潜在关系,这些视图被大多数现有工作视为不透明的过程。我们提出了一个新颖的中间协作框架CMiMC (面向协同感知的对比互信息最大化)。
CMiMC的核心思想是通过最大化协作前和协作后特征之间的互信息来保留协作视图中个体视图的判别信息,同时通过最小化下游任务的损失函数来增强协作视图的有效性。特别地,我们定义了用于中间协作的多视图互信息( MVMI ),它在全局和局部尺度上评估协作视图和个人视图之间的相关性。我们建立了基于多视图对比学习的CMiMNet来实现MVMI的估计和最大化,从而辅助训练一个用于三维像素水平特征融合的协作编码器。我们在V2X - Sim 1.0上评估了CMiMC,在0.5和0.7 IoU ( Intersection-overUnion )阈值下,它将SOTA平均精度分别提高了3.08 %和4.44 %。此外,CMiMC可以在获得与SOTA相当的性能的同时,将通信量减少到1 / 32
目前的大多数工作将中间协作视为一个不透明的过程,并将其近似为深度神经网络,通过训练来优化下游任务或其他指定设计目标的性能。然而,这样的过程可以简化为:它遇到了性能瓶颈,因为仅仅追求优化预定义的目标,就有失去有价值的特性的风险。
Hjelm等人的证据表明,无监督学习生成的特征优于最小化下游损失的监督学习生成的特征。本文旨在研究中间协作中特征聚合的基本原理,探索促成良好协作视图(即,合作后的特征)的特征,以及良好协作视图如何与个体Agent的视图(也就是说,合作前的特征)相关联。
从直觉上讲,协作视图需要聚合个体视图中的所有判别信息。基于这种直觉,我们将互信息( MI )最大化的概念引入到中间协作中。MI最大化最初用于表示学习,用于寻找捕获数据中潜在依赖关系的特征。我们扩展了它的中间协作能力,以获得保留个体视图的信息部分并抛弃无关或冗余视图的协作视图。
Towards Label Efficient
COˆ3: Cooperative Unsupervised 3D Representation Learning for Autonomous Driving
摘要
针对室内场景点云的无监督对比学习已经取得了巨大的成功。然而,室外场景点云的无监督表示学习仍然具有挑战性,因为以前的方法需要重建整个场景并捕获对比目标的部分视图。这在有运动物体、障碍物和传感器的室外场景中是不可行的。在本文中,我们提出了CO ( 3,即协同对比学习和上下文形状预测,以无监督的方式学习室外场景点云的三维表示。与现有方法相比,CO3有几个优点。( 1 )利用车载侧和基础设施侧的LiDAR点云构建足够差异但同时保持共同语义信息的视图进行对比学习,比以往方法构建的视图更合适。( 2 )在对比目标的基础上,提出了上下文形状预测作为预训练目标,为无监督的三维点云表示学习带来了更多与任务相关的信息,有利于将学习到的表示迁移到下游的检测任务中。( 3 )与以往的方法相比,CO ( 3 )学习到的表示可以迁移到不同类型的LiDAR传感器采集的室外场景数据集上。( 4 ) CO ( 3在Once和KITTI d上都改进了当前最先进的方法
介绍
激光雷达作为室外环境中最可靠的传感器,能够精确地测量物体的三维位置,机器人和计算机视觉领域都对激光雷达点云的感知任务表现出强烈的兴趣,包括三维物体检测、分割和跟踪,这些任务对于自动驾驶系统至关重要。迄今为止,在详细的标注数据上从头开始随机初始化和直接训练仍然占据着该领域的主导地位。与此相反,最近图像领域的研究工作侧重于从图像构建具有不同视角对比目标的无监督表示学习
他们以无监督的方式使用ImageNet 等大规模数据集对2D骨干网络进行预训练,并使用预训练的骨干网络在不同的数据集上初始化下游神经网络,在2D目标检测中实现了从头开始训练的显著性能提升。受这些成功的启发,结合自动驾驶车辆中丰富的未 标记数据探索了室外场景点云的无监督表示学习,以提高三维目标检测任务的性能。在过去的十年中,从无标签数据中学习三维表示在单目标和室内场景点云中取得了巨大的成功。对于单个物体的点云,如CAD模型,先前的工作通过最小化对比损失来预训练3D编码器来预测全局表示,并针对包括物体分类和配准在内的低级下游任务。为了将这一思想扩展到室内场景点云的高层感知任务,Point Contrast 提出重建整个室内场景,从两个不同的姿态采集部分点云,并将其作为对比学习中的两个视图来学习稠密的(点级或三维像素水平)表示

General
SiCP: Simultaneous Individual and Cooperative Perception for 3D Object Detection in Connected and Automated Vehicles
传统的车联网和自动驾驶车辆的协同感知是通过融合来自两个或多个车辆的特征图来实现的。然而,与独立的3D检测模型相比,缺乏来自其他车辆的共享特征图会导致协作感知模型的3D目标检测性能显著下降。这一缺陷阻碍了合作感知的采用,因为车辆资源通常不足以同时使用两种感知模型。
为了解决这个问题提出了一个通用的框架,即同时的个人和合作感知( Simultaneous Personal and Cooperative Perception,SiCP ),它支持广泛的最新独立感知主干,并通过一个新颖的双感知网络( Dual-Perception Network,DP-Net )来增强它们,以促进个人和合作感知。除了其仅有0.13 M参数的轻量级特性外,DP - Net具有鲁棒性,并且在特征图融合过程中保留了关键的梯度信息。在V2V4Real和OPV2V数据集上的综合评估表明,得益于DP - Net,SiCP在保持独立感知解决方案性能的同时,超越了最先进的合作感知解决方案。
TransIFF: An Instance-Level Feature Fusion Framework for Vehicle-Infrastructure Cooperative 3D Detection with Transformers
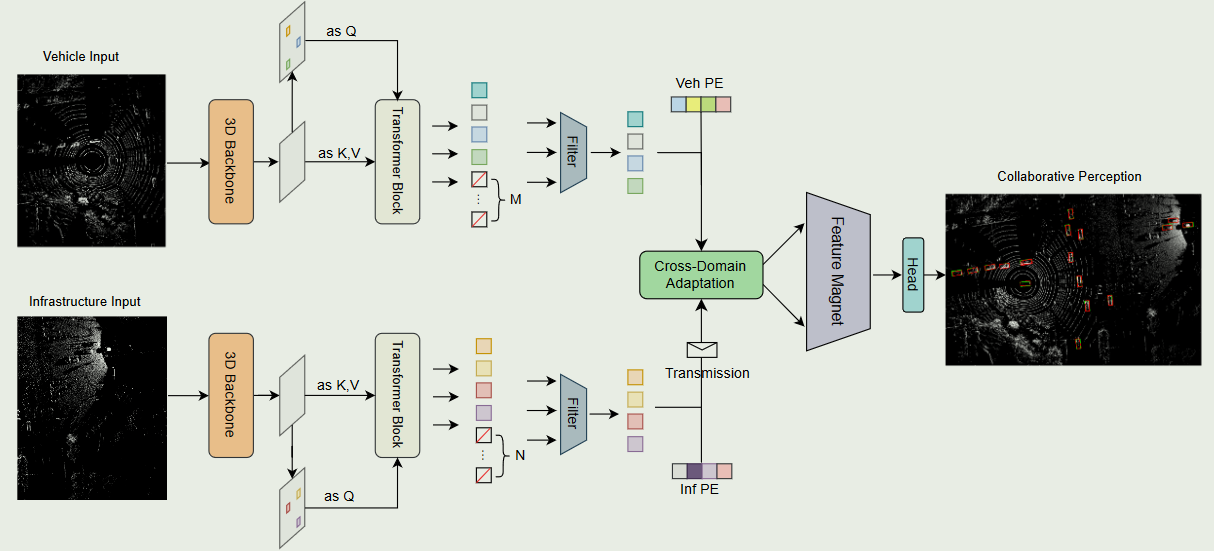
车辆和基础设施之间的合作对于增强自动驾驶的安全性至关重要。协作感知目前面临着两个重大而矛盾的挑战:融合精度和通信带宽。以往传递特征的中级融合方法相比早期融合和后期融合在精度和带宽上取得了平衡,但通常存在feature misalignment和domain gaps的问题,bandwitdth usage仍然达不到工业应用标准
在本文中提出了TransIFF,一种带有Transformer的instance-level特征融合框架,可以有效地减少带宽占用。此外,它可以对齐车辆和基础设施特征之间的域间隙,并提高特征融合的鲁棒性,从而获得较高的协作感知精度
TransIFF由3个部分组成:车辆侧网络、基础设施侧网络和车辆-基础设施融合网络.最初,车辆端和基础设施端网络独立生成实例级特征
最初,车辆端和基础设施端网络独立生成实例级特征。随后,基础设施侧的实例级特征被传输到车辆,显著降低了通信带宽的使用。
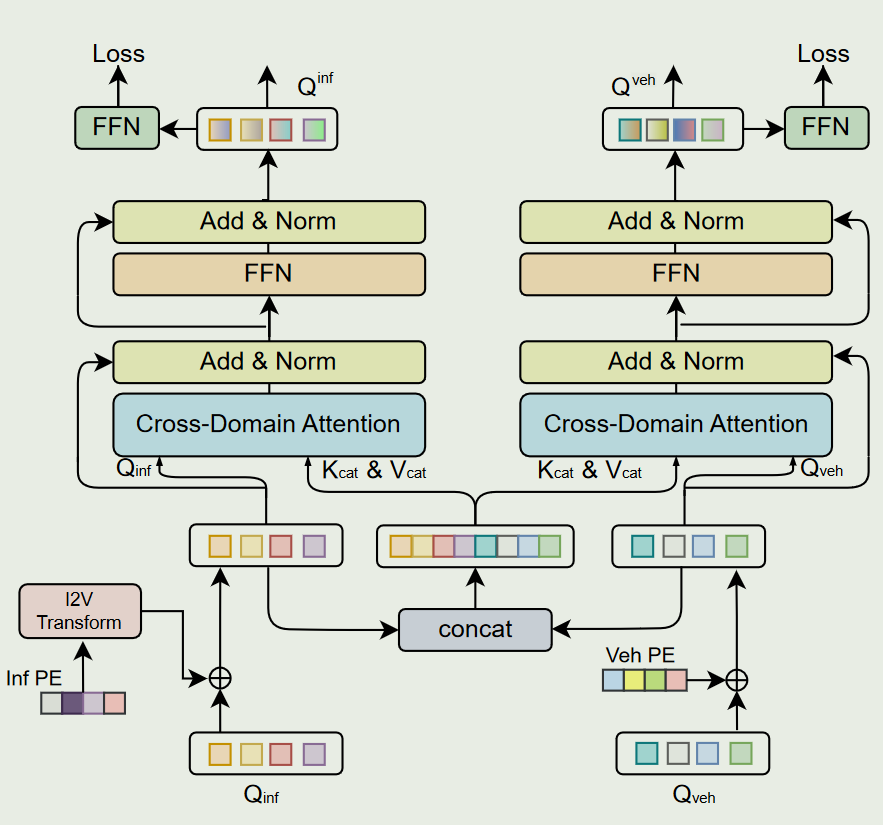
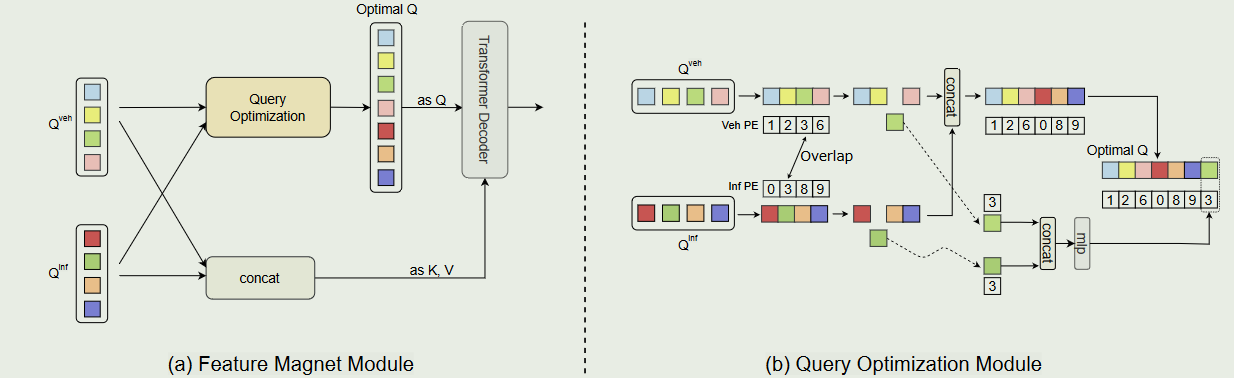
最后,在车路融合网络中,设计了跨域适应( Cross-Domain Adaptation,CDA )模块对齐特征域,紧接着设计了Feature Magnet模块对实例特征进行自适应融合,实现了鲁棒的特征融合
得益于基础设施侧传感器的高安装高度,无人驾驶车辆通过接收基础设施侧传感器的信息,实现全局视角和远距离感知,显著提高了感知能力
车路协同感知面临的挑战之一是信息需要从基础设施侧设备发送到自动驾驶汽车,这需要通信带宽资源。然而,工业通信系统在实时性方面难以承担巨大的通信消耗
因此,如何在保证协作感知准确性的同时降低通信带宽消耗至关重要。中间融合传输特征信息,提供了带宽占用和精度之间的权衡。
然而,尽管与早期融合相比数据量减少,中间融合的带宽占用仍然达不到工业标准。而且,大多数中间融合方法面临空间对齐的挑战,对车辆与基础设施侧设备之间的实时位姿提出了很高的要求,导致特征融合的鲁棒性不足。
此外,来自车辆侧和基础设施侧传感器的特征属于两个域,特征中的域间隙也会影响协同感知的准确性。
在这项工作中,我们提出了一种基于Transformer的鲁棒有效的实例级特征融合框架TransIFF。我们的核心思想是通过传递实例级特征而不是整个特征来减少带宽消耗,同时通过对齐域间隙来提高协同感知的精度,并通过一个可以摆脱对高精度位姿依赖的转换器来实现鲁棒和自适应的特征融合
others
Towards Interactive and Learnable Cooperative Driving Automation: a Large Language Model-Driven Decision-Making Framework
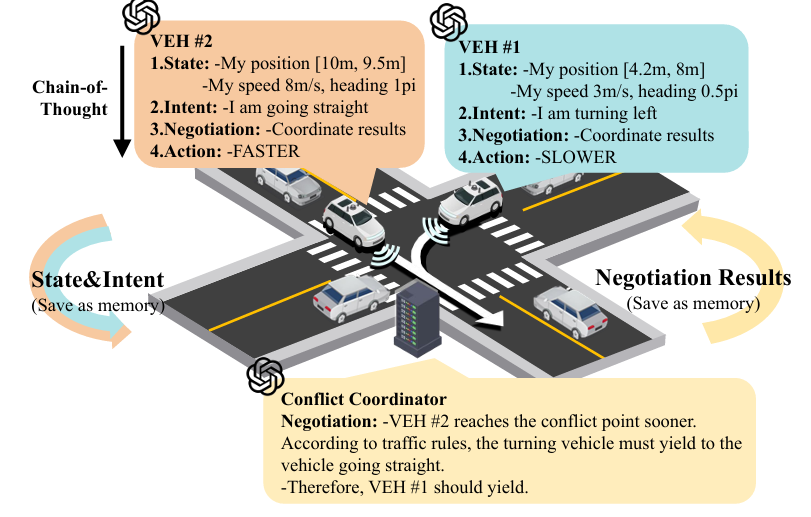
目前,智能网联汽车( Connected Autonomous Vehicles,CAVs )已经开始在世界各地进行开放道路测试,但其在复杂场景下的安全和效率表现仍不尽如人意。协同驾驶利用CAV的连通能力实现大于其部分之和的协同作用,使其成为提高复杂场景下CAV性能的一种有前途的方法。然而,缺乏交互和持续学习能力限制了当前的协同驾驶到单场景应用和特定的协同驾驶自动化( Cooperative Driving Automation,CDA )。为了应对这些挑战,本文提出了一种可交互和学习的LLM驱动的协同驾驶框架CoDrivingLLM,以实现全场景和全CDA.
为了应对这些挑战,本文提出了一种可交互和学习的LLM驱动的协同驾驶框架CoDrivingLLM,以实现全场景和全CDA
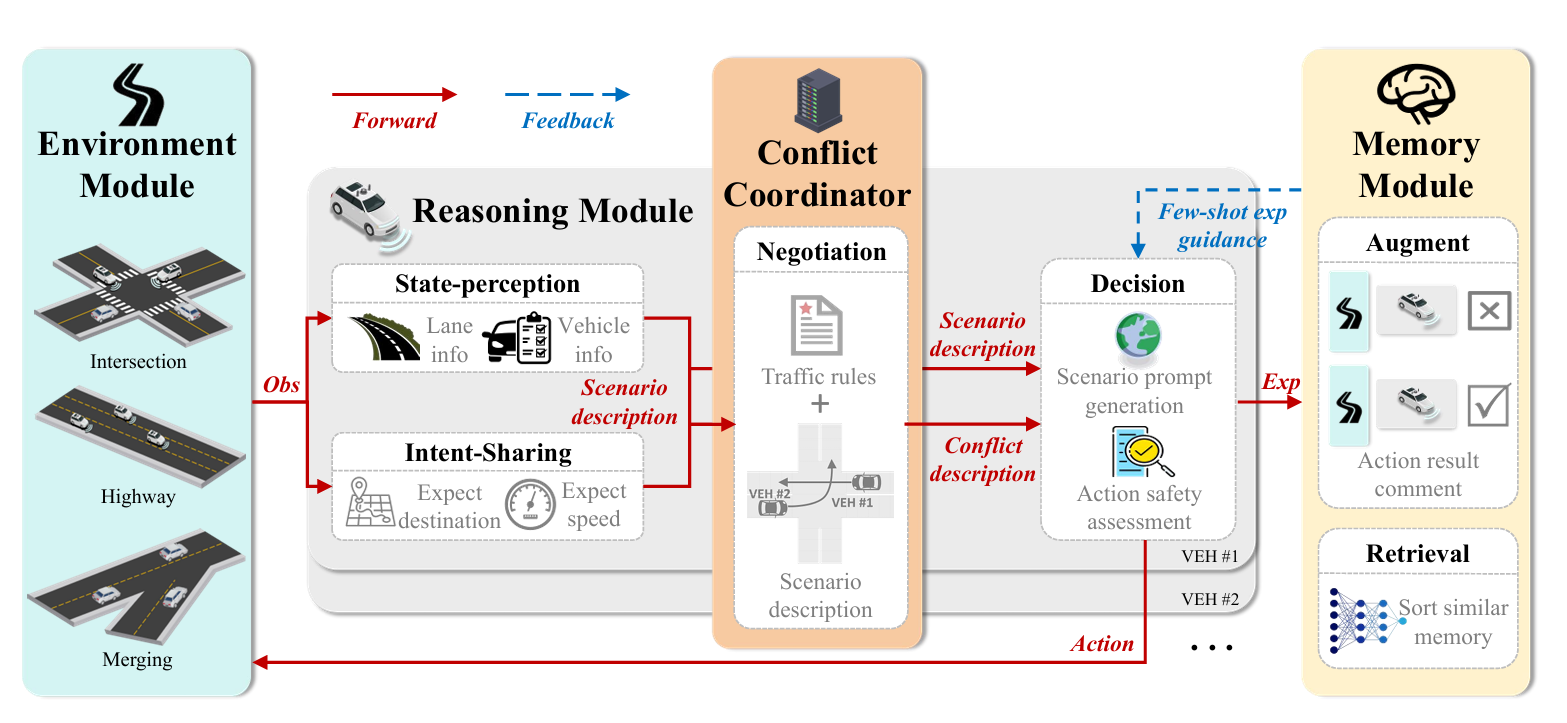
首先,由于大语言模型( Large Language Models,LLMs )不擅长处理数学计算,引入环境模块,基于语义决策更新车辆位置,从而避免直接LLM控制车辆位置可能带来的误差。其次,基于SAE J3216标准定义的CDA的四个层次,我们提出了基于思维链( Chain-of- Thought,COT )的推理模块,包括状态感知、意图共享、协商和决策,增强了LLMs在多步推理任务中的稳定性。然后,在推理过程中,通过冲突协调者来管理集中的冲突解决。最后,通过引入记忆模块和使用提取增强生成,赋予CAVs从过去经验中学习的能力.通过对协商模块的消融实验、不同镜头经验的推理以及与其他协同驾驶方法的对比,验证了所提出的CoDriving LLM。结果表明,我们的方法提供了显著的安全和效率优势,以及在复杂环境中进行有效交互和学习的能力。
几个贡献:
本文提出了一种基于LLM的可交互、可学习的协同驾驶框架CoDrivingLLM,该框架具有集中式-分布式耦合架构的特点。该框架通过对环境模块、推理模块和记忆模块的有效设计和耦合,显著提升了不同场景下的协同驾驶性能。
在推理模块中,设计了状态感知、意图共享、协商和决策4个子模块,以实现不同层次CDA之间的灵活切换。考虑到多车协作的高复杂性,设计了一个推断车辆建议通行顺序的冲突协调器作为协商模块。结果表明,冲突协调器的引入显著提高了车辆的交互能力。
通过引入带有检索增强生成( Retrieval Augment Generation,RAG )的记忆模块,赋予CAVs不断从历史经验中学习的能力。通过寻找与当前情景最相似的记忆,并参考相应的决策,CAVs可以避免重复过去的错误。结果表明,在各种场景和任务中都表现出优异的性能。