从一般的2D目标检测到3D目标检测.3D检测方面主要涉及到自动驾驶领域,这里主要看看论文,涉及到自动驾驶协同感知.
先看几篇论文.
anchor-free detection,脱离了SSD,RetinaNet以及YOLO的anchor-based的工作。
PointNet
abs
点云是一种重要的几何数据结构。由于其不规则的格式,大多数研究人员将此类数据转换为规则的 3D 体素网格或图像集合。但是,这会使数据变得不必要地宽松(voluminous)并导致问题。在本文中,我们设计了一种新型的神经网络,它直接使用点云,它很好地尊重了输入中点的排列不变性。
intro
典型的卷积架构需要高度规则的输入数据格式,如图像网格或 3D 体素格式,以便执行权重共享和其他内核优化。由于点云或网格不是常规格式,因此大多数研究人员通常会将此类数据转换为常规的 3D 体素网格或图像集合(例如视图),然后再将它们馈送到深度网络架构。
然而,这种数据表示转换使生成的数据变得不必要地大量,同时还引入了量化伪影,这些伪影可能会掩盖数据的自然不变性(renders the resulting data unnecessarily voluminous — while also introducing quantization artifacts that can obscure natural invariances of the data.)。
点云是简单而统一的结构,避免了网格的组合不规则性和复杂性,因此更容易学习。
PointNet 是一个统一的架构,它直接将点云作为输入,并输出整个输入的类标签或输入的每个点段/部分标签。在基本设置中,每个点仅由其三个坐标(x、y、z)表示。可以通过计算法线和其他局部或全局特征来添加其他维度。
我们方法的关键是使用单个对称函数,即最大池化。实际上,网络学习了一组优化函数/标准,这些函数/标准选择点云中信息丰富的点,并对其选择的原因进行编码。
网络的最终全连接层将这些学习到的最优值聚合到整个形状的全局描述符中,
输入格式很容易应用刚性或仿射变换,因为每个点都是独立变换的。因此,我们可以添加一个依赖于数据的空间转换器网络,该网络在PointNet处理数据之前尝试对数据进行规范化,从而进一步改善结果。
我们的网络学习通过一组稀疏的关键点来总结输入点云,这大致对应于根据可视化对象的骨架。
点云的大多数现有功能都是针对特定任务手工制作的。点特征通常对点的某些统计属性进行编码,并被设计为对某些变换不变,这些变换通常被归类为内在或外在 。它们还可以分为局部要素和全局要素。对于特定任务,找到最佳特征组合并非易事。
3D 数据具有多种流行的表示形式,从而产生了各种学习方法。体积 CNN是将 3D 卷积神经网络应用于体素化形状的先驱。然而,由于数据稀疏性和三维卷积的计算成本,体积表示受到其分辨率的限制。
我们设计了一个深度学习框架,直接使用无序点集作为输入。点云表示为一组 3D 点 {Pi| i = 1, …, n},其中每个点 Pi 是其 (x, y, z) 坐标加上额外的特征通道(如颜色、法线等)的向量。为了简单明了起见,除非另有说明,否则我们仅使用 (x, y, z) 坐标作为点的通道
对于对象分类任务,输入点云要么直接从形状中采样,要么从场景点云中预先分割。
对于语义分割,输入可以是用于部分区域分割的单个对象,也可以是用于对象区域分割的 3D 场景中的子体积

我们的网络有三个关键模块:最大池化层作为聚合所有点信息的对称函数,局部和全局信息组合结构,以及两个对齐输入点和点特征的联合对齐网络。
Symmetry Function for Unordered Input
为了使模型对输入排列不变,存在三种策略:1)将输入排序为规范顺序;
2)将输入视为训练RNN的序列,但通过各种排列来增强训练数据;
3)使用简单的对称函数来聚合每个点的信息。
对称函数将 n 个向量作为输入,并输出一个与输入顺序不变的新向量。
虽然排序听起来像是一个简单的解决方案,但在高维空间中,实际上并不存在一般意义
上的稳定的点扰动排序。
我们的想法是通过对集合中的变换元素应用对称函数来近似在点集上定义的一般函数
从经验上讲,我们的基本模块非常简单:通过多层感知器网络来近似 h,通过单个变量函数和最大池化函数的组合来近似 g.实验发现这效果很好。通过 h 的集合,我们可以学习多个 f 来捕获集合的不同性质.
Local and Global Information Aggregation
上一节的输出形成一个向量 [f1, . . . , fK ],它是输入集的全局签名。我们可以轻松地在形状全局特征上训练 SVM 或多层感知器分类器进行分类。但是,点分割需要结合本地和全局知识。
在计算出全局点云特征向量后,我们通过将全局特征与每个点特征连接起来,将其反馈给每个点的特征。然后,我们根据组合的点特征提取新的每点特征 - 这一次,每点特征同时识别局部和全局信息。
Joint Alignment Network
如果点云经历某些几何变换(例如刚性变换),则点云的语义标记必须是不变的。因此,我们期望点集的学习表示对于这些变换是不变的。一个自然的解决方案是在特征提取之前将所有输入集对齐到规范空间。Jaderberg等介绍了空间变换器的概念,通过采样和插值来对齐2D图像,这是通过在GPU上实现的专门定制层实现的。
点云数据所代表的目标对某些空间转换应该具有不变性,如旋转和平移等刚体变换
与相比,我们的点云输入形式使我们能够以更简单的方式实现这一目标。我们不需要发明任何新图层,也没有像图像案例那样引入别名。
通过一个微型网络预测一个仿射变换矩阵,并将该变换直接应用于输入点的坐标。小网络本身类似于大网络,由点无关特征提取、最大池化和全连接层等基础模块组成。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37class STN3d(nn.Module):
def __init__(self, channel):
super(STN3d, self).__init__()
self.conv1 = torch.nn.Conv1d(channel, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 9)
self.relu = nn.ReLU()
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
def forward(self, x):
batchsize = x.size()[0] # shape (batch_size,3,point_nums)
x = F.relu(self.bn1(self.conv1(x))) # shape (batch_size,64,point_nums)
x = F.relu(self.bn2(self.conv2(x))) # shape (batch_size,128,point_nums)
x = F.relu(self.bn3(self.conv3(x))) # shape (batch_size,1024,point_nums)
x = torch.max(x, 2, keepdim=True)[0] # shape (batch_size,1024,1)
x = x.view(-1, 1024) # shape (batch_size,1024)
x = F.relu(self.bn4(self.fc1(x))) # shape (batch_size,512)
x = F.relu(self.bn5(self.fc2(x))) # shape (batch_size,256)
x = self.fc3(x) # shape (batch_size,9)
iden = Variable(torch.from_numpy(np.array([1, 0, 0, 0, 1, 0, 0, 0, 1]).astype(np.float32))).view(1, 9).repeat(
batchsize, 1) # # shape (batch_size,9)
if x.is_cuda:
iden = iden.cuda()
# that's the same thing as adding a diagonal matrix(full 1)
x = x + iden # iden means that add the input-self
x = x.view(-1, 3, 3) # shape (batch_size,3,3)
return x
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
之前很少有研究点集上的深度学习。PointNet 是这个方向的先驱。然而,根据设计,PointNet 不会捕获由度量空间点所在的局部结构引起的局部结构,这限制了其识别细粒度模式的能力和对复杂场景的泛化性。
在这项工作中,我们引入了一个分层神经网络,该神经网络将PointNet递归应用于输入点集的嵌套分区。通过利用度量空间距离,我们的网络能够学习具有越来越大的上下文尺度的局部特征。随着进一步观察点集通常以不同的密度进行采样,这导致在均匀密度下训练的网络的性能大大降低,我们提出了新的集合学习层来自适应地组合来自多个尺度的特征。

虽然 PointNet 使用单个最大池化操作来聚合整个点集,但我们的新架构构建了点的分层分组,并沿着层次结构逐步抽象出越来越大的局部区域。
在每个级别上,都会对一组点进行处理和抽象,以生成具有较少元素的新集合。集合抽象层由三个关键层组成:采样层、分组层和 PointNet 层。
采样层从输入点中选择一组点,用于定义局部区域的质心。然后,分组层通过查找质心周围的“相邻”点来构建局部区域集。PointNet 层使用微型 PointNet 将局部区域模式编码为特征向量。
Sampling layer.给定输入点 {x1, x2, …, xn},使用迭代最远点采样 (FPS) 来选择点 {xi1 , xi2 , …, xim } 的子集,使得 xij 是相对于其余点与集合 {xi1 , xi2 , …, xij−1 } 最远的点)。与随机采样相比,在质心数量相同的情况下,它对整个点集的覆盖率更高。与扫描数据分布的向量空间无关的 CNN 相比,我们的采样策略以数据依赖的方式生成感受野。
Grouping layer.该层的输入是大小为 N × (d + C) 的点集和大小为 N ′ × d 的一组质心的坐标。输出是大小为 N ′ × K × (d + C) 的点集组,其中每组对应一个局部区域,K 是质心点邻域中的点数。请注意,K 因组而异,后续的 PointNet 层能够将灵活数量的点转换为固定长度的局部区域特征向量。
PointNet layer:在该层中,输入是数据大小为 N ′×K ×(d+C) 的点的 N ′ 局部区域。输出中的每个局部区域都由其质心和编码质心邻域的局部特征抽象。输出数据大小为 N ′ × (d + C′)。
Robust Feature Learning under Non-Uniform Sampling Density
点集在不同区域具有不均匀的密度是很常见的。这种不均匀性给点集特征学习带来了重大挑战。在密集数据中学习的特征可能无法泛化到稀疏采样区域。因此,针对稀疏点云训练的模型可能无法识别细粒度的局部结构。
理想情况下,我们希望尽可能仔细地检查到一个点集,以捕获密集采样区域中最精细的细节。但是,在低密度区域禁止进行这种仔细检查,因为局部模式可能会因采样缺陷而损坏。在这种情况下,我们应该在更近的地方寻找更大尺度的模式。为了实现这一目标,我们提出了密度自适应PointNet层,当输入采样密度发生变化时,该层可以学习组合来自不同尺度区域的特征。
提出了MSG和MRG.
对方法MSG而言,是对不同半径的子区域进行特征提取后进行特征堆叠,特征提取过程还是采用了PointNet
作者是考虑到上述的MSG方法计算量太大,提出来备选方案MRG。MRG用两个Pointnet对连续的两层分别做特征提取与聚合,然后再进行特征拼接

Objects as Points 2019
Abs
检测是将图像中的物体识别为轴对齐的方框。大多数成功的物体检测器都会枚举几乎所有潜在的物体位置,并对每个位置进行分类。这不仅浪费资源、效率低下,还需要额外的后期处理。在本文中,我们采用了一种不同的方法。我们将物体建模为一个点—其边界框的中心点。
我们的检测器使用关键点估算来寻找中心点,并对所有其他物体属性进行回归,如大小、三维位置、方向甚至姿态。与相应的基于边界框的检测器相比,我们基于中心点的方法 CenterNet 是端到端可微分的,更简单、更快速、更准确。
前置知识

使用中心点作为预测结果,输出是一个热力图.假设 I∈ R^W×H×3^ 是宽度为 W、高度为 H 的输入图像,我们的目标是生成一个关键点热图 ˆ Y∈ [0, 1] ^W/R×H/R×C^,R 是输出跨度,C 是关键点类型的数量(就是类别).使用R = 4 的默认输出跨度。输出步长对输出预测进行下采样.预测值 ˆ Y = 1 对应于检测到的关键点,而 ˆ Y= 0 则是背景。
论文中使用几种不同的全卷积编码器-解码器网络来预测图像 I 中的ˆY:堆叠沙漏网络、上卷积残差网络(ResNet)和深层聚合(DLA)。
对于gtbox中的每个中心(也就是keypoint)会计算出一个低分辨率等效点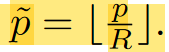
因为预测的输出坐标是经过四倍下采样的,然后利用这个真值通过一个高斯核函数拼接到热图上.我们知道预测的输出是在0-1之间的,而且大小是W/R×H/R×C,利用这个核函数计算每个下采样后的关键点在热力图上的值.其中,σ 是与物体大小相适应的标准偏差,如果同一类别的两个高斯重叠,我们取元素最大值
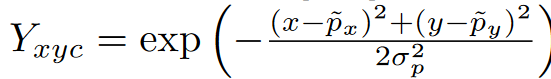
损失使用RetinaNet提出的Focal损失变型.主要是得到预测的中心位置,ground truth没有直接使用,而是使用一个高斯核将不是中心的点的值设置为(0-1),相当于更好地优化了.从简单的0-1到离散值.

此外,因为需要恢复输出跨距造成的离散化误差,还添加了损失.
为每个中心点预测一个局部偏移量 ˆ O∈ R^W/R×H/RX2^。所有类别 c 共享相同的偏移预测,由于输入是一张图像,通过backbone(论文中的是ResNet和DLA)得到downsampling之后的feature map(原文叫heat map)
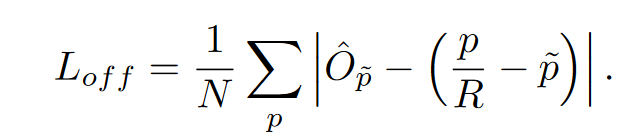
由此得到了物体的中心点,接下来需要回归得到尺寸.
我们使用关键点估计器 ˆ Y 来预测所有中心点。此外,我们对每个对象 k 的对象尺寸 sk = (x(k) 2 - x(k) 1 , y(k) 2 - y(k) 1 ) 进行回归。
对于3D目标检测,还需要得到深度、三维空间和方向。会为每个输出添加一个单独的头部。
深度:深度 d 是每个中心点的单一标量。然而,深度很难直接回归。我们使用 Eigen 等人的输出变换和 d = 1/σ( ˆ d) - 1,其中 σ 是 sigmoid 函数。我们将深度作为关键点估计器的附加输出通道 ˆ D∈[0, 1] W R ×H R 来计算。
物体的三维尺寸是三个标量。使用单独的头
和 L1 损失直接回归到它们的绝对值(以米为单位)。
默认情况下,方向是一个单一标量。但是,很难对其进行回归。效仿 Mousavian 等人的研究,将方向表示为两个bins,并进行bins内回归。具体来说,bin使用 8 个标量编码,每个bin有 4 个标量。对于一个bins,两个标量用于softmax,其余两个标量在每个分区内回归到一个angle。
Range-Aware Attention Network for LiDAR-based 3D Object Detection with Auxiliary Point Density Level Estimation
http://arxiv.org/abs/2111.09515
Abs
近年来,用于自动驾驶的激光雷达数据三维物体检测技术取得了长足进步,在最先进的方法中,将点云编码成鸟瞰图(BEV,bird’s eye view)已被证明是既有效又高效的方法。与透视图(perspective views)不同,鸟瞰图保留了物体之间丰富的空间和距离信息。然而,在 BEV 中,虽然同类型的远距离物体看起来并不更小,但它们包含的点云特征却更稀疏。这一事实削弱了使用共享权重卷积神经网络(CNN)提取 BEV 特征的能力.
为了应对这一挑战,我们提出了范围感知注意力网络 (RAANet),它能提取有效的 BEV 特征并生成出色的 3D object detection 输出.
范围感知注意力(RAA)卷积显著改善了对远近物体的特征提取。
此外,我们还提出了一种用于点密度估计(point density estimation)的新型辅助损失,以进一步提高 RAANet 对遮挡物体的检测精度。值得注意的是,我们提出的 RAA 卷积是轻量级的,可以集成到任何用于检测 BEV 的 CNN 架构中.
在 nuScenes 和 KITTI 数据集上进行的大量实验表明,在基于激光雷达(LiDAR-based 3D object detection)的三维物体检测方面,我们提出的方法优于最先进的方法,在 nuScenes 激光雷达帧上进行的测试中,完整版的实时推理速度为 16 Hz,精简版为 22 Hz。
Intro
随着处理单元的快速改进,得益于深度神经网络的成功,自动驾驶的感知能力近年来得到了蓬勃发展。通过激光雷达传感器进行 3D 物体检测是自动驾驶的重要功能之一。
早期的研究采用了三维卷积神经网络(CNN),这种网络处理速度慢,内存需求大。
为了降低内存要求并提供实时处理,最近的方法利用了体素化(voxelization)和鸟瞰投影(BEV)。
体素化(Voxelization)作为三维点云(3D point clouds)的一种预处理方法得到了广泛应用,因为结构更合理的数据可提高计算效率和性能精度。
一般来说,体素化将点云划分为均匀分布的体素网格,然后将三维激光雷达点分配到各自的体素上。输出空间保留了物体之间的欧氏距离,并避免了边界框的重叠。
这些特点使得无论物体与激光雷达的距离如何,都能将物体的尺寸变化控制在一个相对较小的范围内,从而有利于在训练过程中进行形状回归。
在本文中,我们提出了距离感知注意力网络(RAANet),其中包含新型的范围感知注意力卷积层(RAAConv),设计用于LiDAR BEV的目标检测。RAAConv 由两个独立的卷积分支和注意力图组成,对输入特征图的位置信息敏感.
我们的方法受到BEV图像特性的启发,随着物体和自我车辆之间距离的增加,点变得越来越稀疏。理想情况下,对于BEV特征图,不同位置的元素应由不同的卷积核处理。但是,应用不同的内核会显着增加计算费用。
为了在BEV特征提取过程中利用位置信息,在避免繁重计算的同时,将BEV特征图视为稀疏特征和密集特征的组合。我们应用两个不同的卷积核来同时提取稀疏和密集特征。
每个提取的特征图的通道大小都是最终输出的一半。同时,根据输入形状生成范围和位置编码。然后,根据相应的特征图以及范围和位置编码计算每个范围感知注意力热图。最后,将注意力热图应用于特征图以增强特征表示。从两个分支生成的特征图按通道concat为 RAAConv 输出。
此外,遮挡的影响也不容忽视,因为同一物体在不同的遮挡量下可能具有不同的点分布。因此,我们提出了一个高效的辅助分支,称为辅助密度水平估计模块(ADLE),允许RAANet考虑遮挡。由于注释各种遮挡是一项耗时且昂贵的任务,因此我们设计了ADLE来估计每个对象的点密度水平。如果没有遮挡,则近处物体的点密度水平高于远处物体的点密度水平。
但是,如果附近的物体被遮挡,则其点密度水平会降低。因此,通过结合距离信息和密度水平信息,我们能够估计遮挡信息的存在。ADLE仅用于训练阶段,用于提供密度信息指导,在推理状态下可以删除,以提高计算效率。
主要贡献:
- 我们提出了RAAConv层,它允许基于LiDAR的探测器提取更具代表性的BEV特征。此外,RAAConv 层可以集成到任何用于 LiDAR BEV 的 CNN 架构中。
- 我们提出了一种新的用于点密度估计的辅助损失,以帮助主网络学习与遮挡相关的特征。该密度水平估计器进一步提高了RAANet对被遮挡物体的检测精度。
- 我们提出了范围感知注意力网络(RAANet),它集成了前面提到的RAA和ADLE模块。RAANet通过基于ground truth生成各向异性(anistropic)高斯热图,进一步优化,
相关工作
大多数目标检测工作可以分为两大类:有锚点和无锚点的目标检测。此外,在早期阶段存在对点云数据进行编码的工作],但它们超出了目标检测网络重构的范围。
Object detection with anchors
固定形状的锚回归方法,以便可以提取中间特征
two-stage:RCNN家族
one-stage:YOLO,Retinanet,SSD
YOLO:将目标检测重新定义为单一回归问题,该问题采用端到端神经网络进行单次前向传播来检测目标
SSD:Liu等开发了一种多分辨率锚点技术,用于检测尺度混合物的物体,并在一定程度上学习偏移量,而不是学习锚点。
RetinaNet:Lin等提出了一种焦点损失,以解决密集和小目标检测问题,同时处理类不平衡和不一致。
Zhou和Tuzel(VoxelNet)以及Lang等(PointPillars)提出了用于点云的神经网络,这为3D检测任务开辟了新的可能性。
Object detection without anchors
为了解决锚点回归带来的计算开销和超参数冗余问题,并有效地处理点云编码,无锚点目标检测已在许多工作中得到应用。无锚点目标检测可分为两大类,即基于中心的方法和基于关键点的方法。
基于中心的方法:在这种方法中,对象的中心点用于定义正样本和负样本,而不是IoU。该方法通过预测从正样本到物体边界的四个距离来生成边界框,从而大大降低了计算成本。
基于关键点的方法:通过几个预定义的方法或自学习模型定位关键点,然后生成边界框来对对象进行分类。
为了提取具有代表性的特征,我们重点关注两个主要组成部分:范围感知特征提取和遮挡监督。
我们提出的范围感知注意力网络(RAANet)的主要架构如图所示

我们结合了CenterNet的思想来构建一个无锚探测器,并引入了两个新颖的模块:距离感知注意力卷积层(RAAConv)和辅助密度级估计模块(ADLE)。
区域建议网络 (RPN) 将该 BEV 特征图作为输入,并使用多个下采样和上采样模块来生成高维特征图。
除了主要任务中的检测头外,我们还提出了一个辅助任务,用于点密度水平估计,以实现更好的检测性能。
RAAConv 首先利用两组卷积核来提取每个分支的中间特征图。
然后,将热图 fa 和 fb 分别乘以可学习标量 γa 和 γb。γa 和 γb 初始化为 1.0,并在训练过程中逐渐学习它们的值
VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection 2017
abs
准确检测三维点云中的物体是自主导航、看家机器人和增强/虚拟现实等许多应用中的核心问题。点云数据 高度稀疏
为了将高度稀疏的激光雷达点云与区域建议网络(RPN)连接起来,现有的大部分工作都集中在手工制作的特征表示上,例如鸟瞰投影。
在这项工作中,我们不再需要对三维点云进行人工特征工程,而是提出了一种通用的三维检测网络—VoxelNet,它将特征提取和边界框预测统一为一个单一阶段、端到端可训练的深度网络。
相关工作
3D传感器技术的快速发展促使研究人员开发有效的表示来检测和定位点云中的物体,当有丰富而详细的 3D 形状信息可用时,这些手工制作的特征会产生令人满意的结果。
然而,它们无法适应更复杂的形状和场景,也无法从数据中学习所需的不变性,导致自主导航等不受控制的场景的成功有限。
鉴于图像提供了详细的纹理信息,许多算法从 2D 图像推断出 3D 边界框,然而,基于图像的三维检测方法的精度受深度估计精度的限制。
网络结构
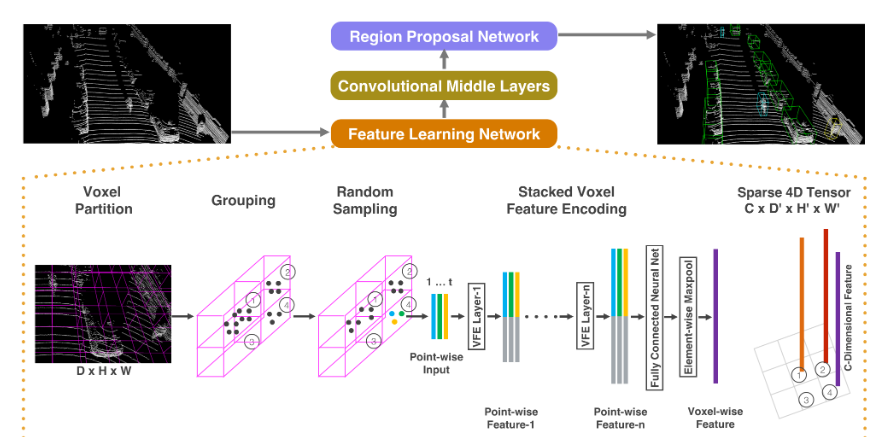
所提出的VoxelNet由三个功能块组成:(1)特征学习网络(Feature learning network),(2)卷积中间层(Convolutional middle layers),(3)区域建议网络(Region proposal network)。
Feature learning network
Voxel Partition

Stacked Voxel Feature Encoding
用V表示一个体素(Voxel),
RPN

RPN层有两个分支,一个用来输出类别的概率分布(通常叫做Score Map),一个用来输出Anchor到真实框的变化过程(通常叫做 Regression Map)
注意这里论文是直接输出预测的anchor box的坐标而不是修正值.
高效实现
我们初始化一个 K × T × 7 维张量结构来存储体素输入特征缓冲区,其中 K 是非空体素的最大数量,T 是每个体素的最大点数,7 是每个点的输入编码维度。
这些点在处理之前是随机的。对于点云中的每个点,我们检查相应的体素是否已经存在。
损失函数
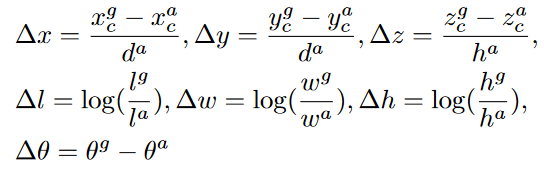
da = √(la)2 + (wa)2 是anchor box的对角线。
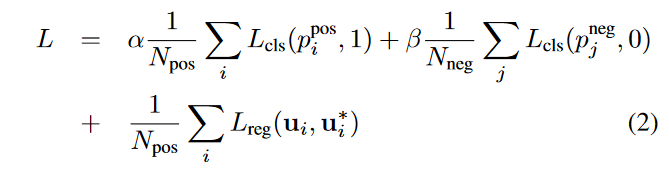
ui ∈ R^7^ 和 u∗ i ∈ R^7^ 分别是正锚点 a^pos^ ~i~ 的回归输出和地面实况。
Center-based 3D Object Detection and Tracking
Introduction
与研究透彻的二维检测问题相比,点云上的三维检测提出了一系列有趣的挑战.点云稀疏,三维空间的大部分区域都没有测量值,其次,输出结果是一个三维方框,通常无法与任何全局坐标框架很好地对齐。第三,三维物体有多种尺寸、形状和长宽比,例如,在交通领域,自行车接近平面,公共汽车和豪华轿车细长,行人高大。
二维和三维检测之间的这些显著差异使得这两个领域之间的理念转换变得更加困难。问题的关键在于,轴对齐的二维方框 并不能代表自由形态的三维物体
一种解决方案可能是为每个物体方向分类不同的模板(锚,但这不必要地增加了计算负担,并可能带来大量潜在的假阳性检测。我们认为,将二维和三维领域连接起来的主要挑战在于物体的这种表现形式。
然后,它将这一表示法扁平化为俯视地图视图,并使用标准的基于图像的关键点检测器来查找对象中心,对于每个检测到的中心点,它会根据中心点位置的点特征回归到所有其他物体属性,如三维尺寸、方向和速度。
基于中心的表示法有几个主要优点:首先,与边界框不同,点没有固有方向。这大大缩小了物体检测器的搜索空间,同时允许骨干学习物体的旋转不变性和相对旋转的旋转等差性。其次,基于中心的表示法简化了追踪等下游任务。如果物体是点,小轨迹就是空间和时间中的路径。中心点可以预测连续帧之间物体的相对偏移(速度),然后将其贪婪地连接起来。第三,基于点的特征提取使我们能够设计一个有效的两阶段细化模块,其速度比以往的方法快得多

CenterPoint 的第一阶段预测特定类别的热图、物体大小、子象素位置细化、旋转和速度。所有输出均为密集预测。
Center heatmap head.
中心头的目标是在检测到的任何物体的中心位置生成一个热图峰值。该头会生成 K 个通道的热图 ˆ Y,K 个类别中的每个类别都有一个通道。
在训练过程中,它的目标是将注释边界框的三维中心投影到地图视图中产生的二维高斯。我们使用focal损耗
自上而下地图视图中的物体比图像中的要稀疏。在地图视图中,距离是绝对的,而在图像视图中,距离会因透视而扭曲。以道路场景为例,在地图视图中,车辆所占的面积很小,但在图像视图中,几个大物体可能占据了屏幕的大部分区域
采用 CenterNet的标准监督方式会导致监督信号非常稀疏,大多数位置都被视为背景。为了解决这个问题,我们通过扩大每个地面实况对象中心的高斯峰值,来增加目标热图 Y 的正向监督。
Regression heads
在物体的中心特征处存储了几个物体属性:子象素位置细化(sub-voxel) o∈R2、离地高度 hg∈R、三维尺寸(3D dimension)s∈R3,以及偏航旋转角度(sin(α), cos(α))∈R2。
子体素位置细化 o 可减少主干网络体素化和跨距造成的量化误差
地面高度 hg 可帮助定位三维物体,并补充地图视图投影中缺失的高程信息。
方位预测使用偏航角的正弦和余弦作为连续回归目标。
结合方框大小,这些回归头可提供三维边界框的全部状态信息。每个输出都使用自己的回归头。在训练时,只使用 L1 回归损失对地面实况中心进行监督。
Two-Stage CenterPoint
第二阶段从骨干网的输出中提取额外的点特征。
我们从预测边界框的每个面的三维中心提取一个点特征。请注意,边界框中心、顶面和底面中心在地图视图中都投影到同一个点。
因此,我们只考虑四个朝外的方框面和预测的物体中心。对于每个点,我们使用双线性插值法从骨干地图视图输出 M 中提取特征。
第二阶段在单阶段 CenterPoint 预测结果的基础上,预测与类别无关的置信度得分和box refinement。
对于不区分类别的置信度得分预测,遵循的方法,使用得分目标 I,该目标由方框的 3D IoU 和相应的地面实况边界方框引导
IoUt 是第 t 个建议框与gt bbox之间的 IoU
在推理过程中,直接使用单阶段中心点的类别预测,并以两个分数的几何平均值计算最终置信度分数
其中 ˆ Qt 是对象 t 的最终预测置信度,ˆ Yt = max0≤k≤K ˆ Yp,k 和 ˆ It 分别是对象 t 的第一阶段和第二阶段置信度。
对于bbox回归,模型在第一阶段建议的基础上预测细化,用 L1 损失来训练模型。
SECOND: Sparsely Embedded Convolutional Detection 2018
PointPillars: Fast Encoders for Object Detection from Point Clouds 2018
PIXOR: Real-time 3D Object Detection from Point Clouds 2019
Keypoints-Based Deep Feature Fusion for Cooperative Vehicle Detection of Autonomous Driving 2021
CIA-SSD: Confident IoU-Aware Single Stage Object Detector From Point Cloud 2021
协同感知 3D检测任务
综述
Collaborative Perception in Autonomous Driving:Methods,Datasets and Challenges
协作感知对于解决自动驾驶中的遮挡和传感器故障问题至关重要。
自动驾驶感知可分为个体感知和协作感知。虽然个体感知随着深度学习的发展取得了长足的进步,但一些问题也限制了其发展。首先,个体感知在感知相对全面的环境时经常会遇到遮挡。其次,车载传感器在感知远处物体时存在物理限制。此外,传感器噪音也会降低感知系统的性能。为了弥补个体感知的不足,协作或合作感知利用了多个代理之间的互动,受到了广泛关注。
协同感知是一种多agent系统,其中agent共享感知信息,以克服自我视听的视觉局限。在单个感知场景中,自我视听只能检测到附近物体的部分遮挡和远处稀疏的点云。在协作感知场景中,ego AV通过接收其他agent的信息来扩大视野。通过这种协作方式,ego AV不仅能检测到远处和被遮挡的物体,还能提高在密集区域的检测精度。
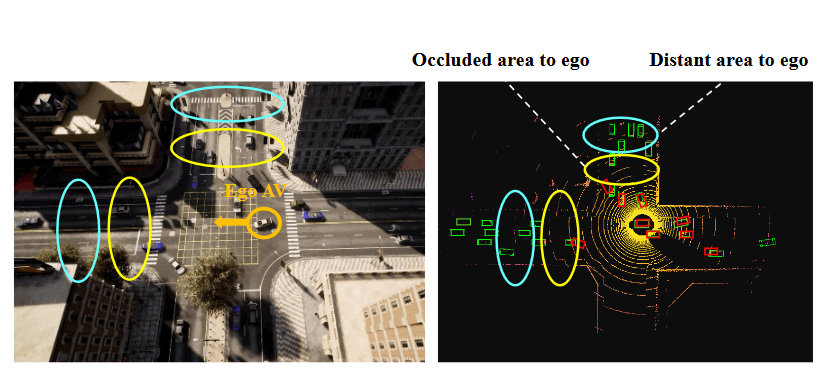
长期以来,协作感知一直是人们关注的焦点。之前的工作专注于构建协作感知系统,以评估该技术的可行性。然而,由于缺乏大型公共数据集,它没有得到有效的推进。近年来,随着深度学习的发展和大规模协作感知数据集的公众关注和研究激增。
考虑到通信中的带宽限制,大多数研究人员致力于设计新颖的协作模块,以实现精度和带宽之间的权衡。
在协作感知场景中,自我 AV 通过接收来自其他智能体的信息来扩展视野。通过这种协作方式,自我AV不仅可以检测远处和被遮挡的物体,还可以提高密集区域的检测精度。
为了总结这些技术和问题,我们回顾了自动驾驶中的协同感知方法,并从方法、数据集和挑战方面对近年来的进展进行了全面综述。我们还注意到近年来发表了一些关于协作感知的综述。
Collaboration scheme
早期融合
早期协作在网络输入端采用原始数据融合,也称为数据级或低级融合
因此,早期协作可以从根本上克服个体感知中的遮挡和长距离问题,并最大程度地促进绩效。
在自动驾驶场景中,自我车辆接收并转换来自其他智能体的原始传感器数据,然后聚合车载转换后的数据。原始数据包含最全面的信息和实质性的代理描述。因此,早期协作可以从根本上克服个体感知中的遮挡和长距离问题,并最大程度地促进绩效。
考虑到早期协作的高带宽,一些工作提出了中间协作感知方法来平衡性能-带宽的权衡。在中间协作中,其他智能体通常会将深层语义特征转移到自我载体。自我车辆融合特征以做出最终预测。中间协作已成为最流行的多智能体协作感知灵活性选择。然而,特征提取往往会造成信息丢失和不必要的信息冗余,这促使人们探索合适的特征选择和融合策略。
中期
考虑到早期协作的高带宽,一些研究提出了中间协作感知方法,以平衡性能与带宽之间的权衡。在中间协作中,其他代理通常会将深层语义特征传输给自我车辆。
晚期
后期或对象级协作在网络输出端采用预测融合。每个代理单独训练网络并相互共享输出。自我车辆在空间上转换输出,并在后处理后合并所有输出。后期协作比早期和中期协作更节省带宽,也更简单。然而,后期的合作也有局限性。由于单个输出可能是嘈杂和不完整的,因此后期协作总是具有最差的感知性能。
原始数据融合(Raw Data Fusion)
早期协作在输入阶段采用原始数据融合。由于点云是不规则的,可以直接汇总,因此早期的协同工作通常采用点云融合策略。
第一个早期的协同感知系统 Cooper选择激光雷达数据作为融合目标。只需提取位置坐标和反射值,就能将点云压缩成较小的尺寸。在代理之间进行交互后,Cooper 利用变换矩阵重构接收到的点云,然后将自我点云集concat起来,进行最终预测。
受 Cooper 的启发,Coop3D 还探索了早期的协作,并引入了一种新的点云融合方法。具体来说,Coop3D 系统没有采用串联,而是利用空间变换来融合传感器数据。此外,与Cooper在车上共享车对车信息不同,Coop3D提出了一个中央系统来合并多个传感器数据,从而可以协同摊销传感器和处理成本。
customized communication mechanism
早期协作中的原始数据融合拓宽了自我飞行器的视野,也造成了高带宽压力。为了缓解上述问题,越来越多的工作 发展了中间协作。
最初的中间协作方法遵循一种贪婪的通信机制,以获取尽可能多的信息。一般来说,它们会与通信范围内的所有代理共享信息,并将压缩后的完整特征图放入集体感知信息(CPM,collective perception message)中。然而,由于特征稀疏和代理冗余,贪婪通信可能会极大地浪费带宽。
Who2com 建立了首个带宽限制下的通信机制,通过三阶段握手实现。具体来说,Who2com 使用一般注意力函数计算代理之间的匹配分数,并选择最需要的代理,从而有效减少带宽。
在 Who2com 的基础上,When2com引入了缩放一般注意力来决定何时与他人交流。这样,自我代理只有在信息不足时才会与他人交流,从而有效地节省了协作资源。
除了选择合适的通信代理外,通信内容对于减少带宽压力也很重要。FPVRCNN 中提出了初始特征选择策略.具体来说,FPV-RCNN 采用检测头生成proposals,并只选择proposals中的特征点。
关键点选择模块减少了共享深度特征的冗余,为初始proposals提供了有价值的补充信息。
Where2comm 也提出了一种新颖的空间信心感知通信机制。其核心思想是利用空间置信度图来决定共享特征和通信目标。在特征选择阶段,Where2comm 选择并传输满足高置信度和其他agent请求的空间元素。在agent选择阶段,自我代理只与能提供所需特征的代理通信。通过发送和接收感知关键区域的特征,Where2comm 节省了大量带宽,并显著提高了协作效率。
Feature Fusion
Feature fusion module is crucial in intermediate collaboration. After receiving CPMs from other agents, the ego vehicle can leverage different strategies to aggregate these features.
可行的融合策略能够捕捉特征之间的潜在关系,提高感知网络的性能。根据基于特征融合的思想,我们将现有的特征融合方法分为传统融合、基于图的融合和基于注意力的融合。
传统融合
在协同感知研究的早期阶段,研究人员倾向于使用传统的策略来融合特征,如concat、求和和线性加权。中级协作将这些不变的置换操作应用于深度特征,因其简单性而实现了快速推理。
第一个中间协同感知框架 FCooper提取了低级体素和深度空间特征。基于这两级特征,F-Cooper 提出了两种特征融合策略:体素特征融合(VFF)和空间特征融合(SFF)。
这两种方法都采用元素最大值(element-wise maxout)来融合重叠区域的特征。由于体素特征更接近原始数据,因此 VFF 与原始数据融合方法一样能够进行近距离物体检测。同时,SFF 也有其优势。
受 SENet的启发,SFF 选择选择部分信道来减少传输时间消耗,同时保持可比的检测精度
考虑到 F-Cooper忽略了低置信度特征的重要性,Guo 等人提出了 CoFF 来改进 F-Cooper。CoFF 通过测量重叠特征的相似度和重叠面积对其进行加权。相似度越小,距离越大,邻近特征提供的补充信息就越直观。
此外,还添加了一个增强参数,以提高弱特征的值。
实验表明,简单而高效的设计使 CoFF 大大提高了 F-Cooper 的性能。
传统的融合方法虽然简单,但并没有被最近的方法所抛弃。Hu 等人提出了协作式纯相机三维检测(CoCa3D),证明了协作在增强基于相机的三维检测方面的潜力。由于深度估计是基于相机的 3D 检测的瓶颈,因此 CoCa3D 包含协作深度估计 (Co-Depth),但协作特征学习 (Co-FL) 除外。
图融合
基于图的融合:尽管传统的中间融合很简单,但它们忽略了多方agent之间的潜在关系,无法推理从发送方到接收方的信息。图神经网络(GNN)能够传播和聚合来自邻居的信息,最近的研究表明,图神经网络在感知和自动驾驶方面非常有效。
V2VNet 首先利用空间感知图神经网络(GNN)对代理之间的通信进行建模,在 GNN 信息传递阶段,V2VNet 利用变分图像压缩算法来压缩特征。在跨车辆聚合阶段,V2VNet 首先补偿时间延迟,为每个节点创建初始状态,然后对从邻近代理到自我车辆的压缩特征进行扭曲和空间变换,所有这些操作都在重叠视场中(overlapping fields of view)进行。在特征融合阶段,V2VNet 采用平均运算来聚合特征,并利用卷积门控递归单元(ConvGRU)更新节点状态。虽然 V2VNet与 GNN 相比性能有所提高,但标量值协作权重无法反映不同空间区域的重要性。受此启发,DiscoNet 提出使用矩阵值边缘权重来捕捉高分辨率的代理间注意力。在信息传递过程中,DiscoNet 将特征串联起来,并为特征图中的每个元素应用矩阵值边缘权重。此外,DiscoNet 还将早期融合和中期融合结合在一起,通过对特征图中的每个元素应用矩阵值边缘权重。zhou 等人提出了另一种基于 GNN 的广义感知框架 MP-Pose。在信息传递阶段,MP-Pose 利用空间编码网络编码相对空间关系,而不是直接扭曲特征。受图形注意网络(GAT)的启发,MP-Pose 进一步使用动态交叉注意编码网络来捕捉代理之间的关系,并像 GAT 一样聚合多个特征。
Attention-based
除了图形学习,注意力机制也已成为探索特征关系的有力工具.注意机制可根据数据域分为通道注意、空间注意和通道与空间注意
在过去的十年中,注意力机制在计算机视觉领域发挥了越来越重要的作用 ,并激发了协作感知研究。
为了捕捉特征图中特定区域之间的相互作用,Xu 等人提出了 AttFusion,并首先在准确的空间位置采用自注意操作。具体来说,AttFusion 引入了单头自注意融合模块,与传统方法 F-Cooper和基于图的方法 DiscoNet相比,实现了性能和推理速度之间的平衡。
除了传统的基于注意力的方法,基于transformer的方法也能激发协作感知。Cui 等人提出了基于点transformer的 COOPERNAUT,这是一种用于点云处理的自注意力网络。
接收到信息后,ego agent会使用下采样块和点transformer block来聚合点特征。这两种操作都保持了信息的排列不变性。更重要的是,COOPERNAUT 将协同感知与控制决策相结合,这对自动驾驶的模块联动具有重要意义
与 V2V 协作相比,V2I 可以利用大量基础设施提供更稳定的协作信息,但目前很少有研究关注这一场景。
Xu 等人提出了首个统一转换器架构(V2X-ViT),它同时涵盖了 V2V 和 V2I。为了在不同类型的agent之间建立互动模块,V2X-ViT 提出了一个新颖的异构多代理关注模块(HMSA)来学习 V2V 和 V2I 之间的不同关系。此外,还引入了多尺度窗口注意模块(MSwin),以捕捉高分辨率检测中的长距离空间交互。
定制损失函数:虽然 V2V 通信为自我车辆提供了相对丰富的感知视野,但共享信息的冗余性和不确定性带来了新的挑战。
以往的协作感知研究大多侧重于协作效率和感知性能,但所有这些方法都假设了完美的条件。在现实世界的自动驾驶场景中,通信系统可能存在以下问题
1) 定位错误;2) 通信延迟和中断;3) 模型或任务差异;4) 隐私和安全问题
协同感知数据集
V2X-Sim是一个全面的模拟多代理感知数据集。它由交通模拟 SUMO 和 CARLA 模拟器生成,数据格式遵循 nuScenes 。V2X-Sim 配备了 RGB 摄像头、激光雷达、GPS 和 IMU,收集了 100 个场景共 10,000 个帧,每个场景包含 2-5 辆车。V2X-Sim 中的帧分为 8,000/1,000/1,000 帧,用于训练/验证/测试。V2X-Sim 的基准支持三个关键的感知任务:检测、跟踪和分割,需要注意的是,所有任务都采用鸟瞰(BEV)表示法,并以二维 BEV 生成结果。
OPV2V:OPV2V是另一个针对V2V通信的模拟协同感知数据集,它是通过协同模拟框架OpenCDA和CARLA模拟器收集的。整个数据集可通过提供的配置文件进行重现。OPV2V 包含 11,464 帧激光雷达点和 RGB 摄像机。OPV2V 的一个显著特点是提供了一个名为 “卡尔弗城 “的仿真测试集,可用于评估模型的泛化能力。其基准支持三维物体检测和 BEV 语义分割,目前只包含一种类型的物体(车辆)。
- V2XSet 是一个大规模的 V2X 感知开放模拟数据集。该数据集格式与 OPV2V类似,共有 11,447 个帧。与 V2X 协作数据集 V2X-Sim和 V2I 协作数据集 DAIR-V2X相比,V2XSet 包含更多场景,并且该基准考虑了不完美的真实世界条件。该基准支持 3D 物体检测和 BEV 分割,有两种测试设置(完美和嘈杂)供评估。
- DAIR-V2X:作为第一个来自真实场景的大规模 V2I 协同感知数据集,DAIR-V2X [对自动驾驶的协同感知意义重大。DAIR-V2X-C 集可用于研究 V2I 协作,VIC3D 基准可用于探索 V2I 物体检测任务。与主要关注激光雷达点的 V2X-Sim和 V2XSet不同,VIC3D 物体检测基准同时提供了基于图像和基于激光雷达点的协作方法。
- V2V4Real:V2V4Real 是首个大规模真实世界多模式 V2V 感知数据集,由俄亥俄州哥伦布市的一辆特斯拉汽车和一辆福特 Fusion 汽车收集而成,覆盖 410 公里的道路。该数据集包含 20,000 个 LiDAR 帧和超过 240,000 个三维边界框注释,涉及五个不同的车辆类别。此外,V2V4Real 还提供了三个合作感知任务的基准,包括三维物体检测、物体跟踪和域适应。
VoxelNet
在这项工作中,我们消除了对 3D 点云进行手动特征工程的需要,并提出了 VoxelNet,这是一种通用的 3D 检测网络,将特征提取和边界框预测统一到一个单阶段、端到端可训练的深度网络中。具体来说,VoxelNet 将点云划分为等间距的 3D 体素,并通过新引入的体素特征编码 (VFE) 层将每个体素内的一组点转换为统一的特征表示。通过这种方式,点云被编码为描述性体积表示,然后将其连接到RPN以生成检测。


Point Pillar
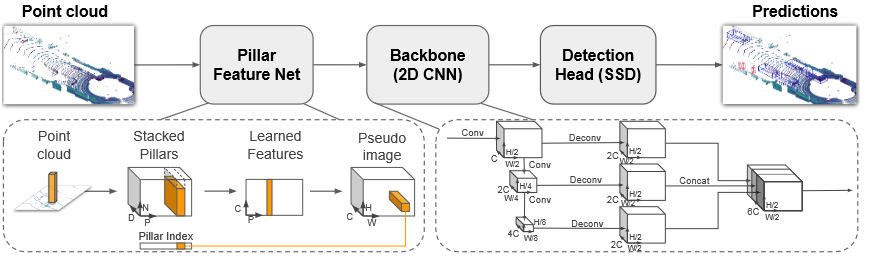
点云中的物体检测是许多机器人应用(如自动驾驶)的一个重要方面。在本文中,我们考虑了将点云编码为适合下游检测管道的格式的问题。最近的文献提出了两种类型的编码器;固定编码器往往速度快,但会牺牲准确性,而从数据中学习的编码器更准确,但速度较慢。在这项工作中,我们提出了PointPillars,这是一种新颖的编码器,它利用PointNets来学习以垂直列(柱子)组织的点云的表示。虽然编码特征可以与任何标准的 2D 卷积检测架构一起使用,但我们进一步提出了一个精益的下游网络。广泛的实验表明,PointPillars 在速度和精度方面都远远优于以前的编码器。尽管只使用激光雷达,但我们的完整检测流程在3D和鸟瞰图KITTI基准测试方面都明显优于最先进的技术,即使在融合方法中也是如此。这种检测性能是在 62 Hz 下运行时实现的:运行时间提高了 2 - 4 倍。我们方法的更快版本与105 Hz的最新技术相匹配。这些基准测试表明,PointPillars 是用于点云中对象检测的合适编码。
SECOND
近年来,基于卷积神经网络(CNN)的目标检测[、实例分割[3]和关键点检测[4]取得了长足的进步。这种检测形式可用于基于单目或立体图像的自动驾驶。但是,用于处理图像的方法不能直接应用于LiDAR数据。这对于自动驾驶和机器人视觉等应用来说是一个重大限制。最先进的方法可以实现 90% 的 2D 汽车检测的平均精度 (AP),但对于基于 3D 图像的汽车检测,AP 仅为 15%。
为了克服仅靠图像提供的空间信息不足的问题,点云数据在 3D 应用中变得越来越重要。点云数据包含准确的深度信息,可以由LiDAR或RGB-D相机生成。
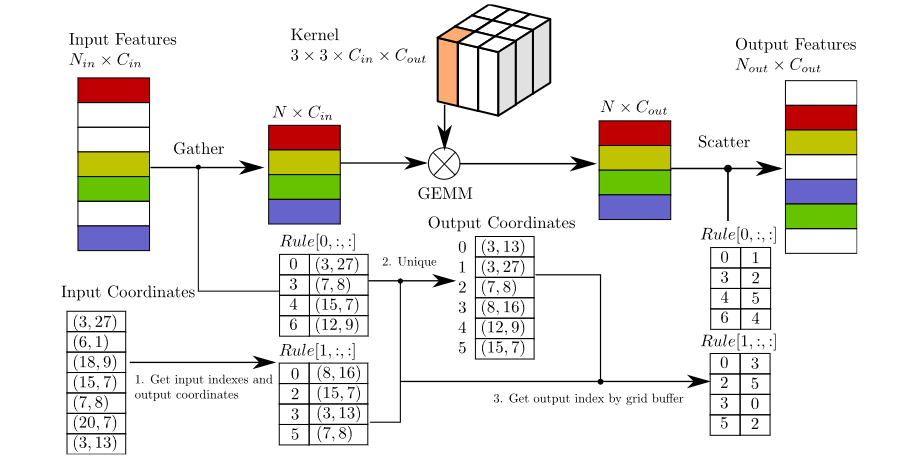
我们在基于LiDAR的目标检测中应用了稀疏卷积,从而大大提高了训练和推理的速度。• 我们提出了一种改进的稀疏卷积方法,使其运行得更快。
• 我们提出了一种新的角度损失回归方法,该方法显示出比其他方法更好的方向回归性能。
• 我们针对仅激光雷达的学习问题引入了一种新的数据增强方法,大大提高了收敛速度和性能。
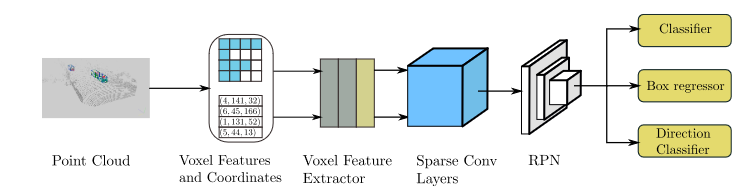
PIXOR
abs
由于点云的高维数,现有方法的计算成本很高。我们通过鸟瞰图(BEV)表示场景,更有效地利用3D数据,并提出了PIXOR,这是一种无需提案的单级检测器,可输出从像素级神经网络预测解码的定向3D对象估计值。
intro
处理激光雷达数据的主要困难在于,传感器以点云的形式生成非结构化数据,通常每 360 度扫描包含大约 105 个 3D 点。
现有的表示主要分为两种类型:3D 体素网格和 2D 投影。
3D 体素网格将点云转换为规则间隔的 3D 网格,其中每个体素单元可以包含标量值(例如,占用率)或矢量数据(例如,根据该体素单元内的点计算出的手工统计数据)。然而,由于点云本质上是稀疏的,因此体素网格非常稀疏,因此很大一部分计算是冗余和不必要的。因此,使用此表示 的典型系统只能以 1-2 FPS 的速度运行
另一种方法是将点云投影到平面上,然后将其离散化为基于2D图像的表示,其中应用了2D卷积,在离散化过程中,手工制作的要素(或统计数据)将计算为 2D 图像的像素值.这些基于 2D 投影的表示更紧凑,但它们会在投影和离散化过程中带来信息丢失。例如,范围视图投影将具有扭曲的对象大小和形状.为了减轻信息损失,MV3D [3] 建议将 2D 投影与相机图像融合以带来更多信息。
我们选择 BEV 表示,因为它在计算上比 3D 体素网格更友好,并且还保留了度量空间,这使我们的模型能够探索有关对象类别的大小和形状的先验.
我们的探测器在鸟瞰图中以真实世界的尺寸输出精确定向的边界框。请注意,这些是 3D 估计值,因为我们假设物体在地面上。在自动驾驶场景中,这是一个合理的假设,因为车辆不会飞行。

我们的边界框估计不仅包含3D空间中的位置,还包含航向角,因为准确预测对于自动驾驶非常重要。我们利用了激光雷达点云的 2D 表示,因为与 3D 体素网格表示相比,它更紧凑,因此更适合实时推理。
Input Representation
标准卷积神经网络执行离散卷积,因此假设输入位于网格上。然而,3D点云是非结构化的,因此不能直接应用标准卷积。
一种选择是使用体素化形成 3D 体素格网,其中每个体素单元格包含该体素内点的某些统计数据。为了从此 3D 体素网格中提取特征表示,通常使用 3D 卷积。然而,这在计算中可能非常昂贵,因为我们必须沿着三维滑动 3D 卷积核。这也是不必要的,因为激光雷达点云非常稀疏,以至于大多数体素像元都是空的。
相反,我们可以仅从鸟瞰图 (BEV) 来表示场景。
通过将自由度从 3 减少到 2,我们不会丢失点云中的信息,因为我们仍然可以将高度信息保留为沿第三维的通道(如 2D 图像的 RGB 通道)。
在自动驾驶的背景下,这种降维是合理的,因为感兴趣的对象位于同一地面上。除了计算效率外,BEV表示还具有其他优势。它缓解了对象检测的问题,因为对象彼此不重叠(与前视图表示相比)。它还保留了度量空间,因此网络可以利用有关对象物理尺寸的先验。
体素化激光雷达表示的常用特征是占用率、强度(反射率)、密度和高度特征。在PIXOR中,为了简单起见,我们只使用占用率和强度作为特征。在实践中,我们首先定义我们感兴趣的场景的 3D 物理尺寸 L × W × H。
然后,我们计算网格分辨率为 d~L~ × d~W~ × d~H~ 的占用特征图,并计算网格分辨率为 d~L~ × d~W~ × H 的强度特征图。请注意,在占用特征图中添加了两个额外的通道,以覆盖超出范围的点。
最终表示的形状为 L /d~L~ × W/d~W~ × ( H/d~H~ + 3)。
Network Architecture
PIXOR 使用全卷积神经网络,专为密集定向 3D 目标检测而设计。我们不采用常用的提案生成分支.取而代之的是,该网络在单个阶段输出像素级预测,每个预测对应于 3D 对象估计。
由于采用了全卷积架构,可以非常有效地计算出如此密集的预测。
在网络预测中 3D 对象的编码方面,我们使用直接编码,而不求助于预定义的对象锚点.
所有这些设计使PIXOR变得非常简单,并且由于网络架构中的零超参数,可以很好地泛化。具体来说,不需要设计对象锚点,也不需要调整从第一阶段传递到第二阶段的提案数量以及相应的非 Non-Maximum Suppression 阈值。
整个架构可以分为两个子网:backbone和header。
backbone网络用于以卷积特征图的形式提取输入的一般表示。它具有很高的表示能力,可以学习鲁棒的特征表示。
header网络用于进行特定于任务的预测,在我们的示例中,它有多任务输出的单分支结构:表示对象类概率的分数图,以及编码定向 3D 对象的大小和形状的几何图。
Backbone Network
卷积神经网络通常由卷积层和池化层组成.
许多基于图像的物体检测器中的骨干网络通常具有 16 的下采样因子,并且通常设计为高分辨率层数较少,低分辨率层数较多。它适用于图像,因为对象的像素大小通常很大。但是,在我们的例子中,这将导致一个问题,因为对象可能非常小。使用 0.1m 的离散化分辨率时,典型车辆的尺寸为 18×40 。经过 16× 的下采样后,它仅覆盖大约 3 个像素。一个直接的解决方案是使用更少的池化层。然而,这将减小最终特征图中每个像素的感受野的大小,从而限制了表示能力。然而,这会导致高级特征图中出现棋盘伪影。我们的解决方案很简单,我们使用 16× 的下采样因子,但进行了两次修改。
首先,我们在较低的级别中添加更多具有较小通道数的层,以提取更精细的细节信息。其次,我们采用类似于FPN的自上而下的分支,将高分辨率特征图与低分辨率特征图相结合,从而对最终的特征表示进行上采样

第二至第五块由残余层组成,每个残差块的第一个卷积的步幅为 2,以便对特征图进行下采样。总的来说,我们的下采样因子为 16。为了对特征图进行上采样,我们添加了一个自上而下的路径,每次对特征图进行上采样 2。
然后通过像素求和将其与相应分辨率的自下而上的特征图相结合。使用两个上采样层,从而得到最终的特征图,相对于输入,下采样因子为 4×。
Header Network
Header 网络是一个多任务网络,可处理对象识别和定位。
分类分支输出 1 通道特征图,后跟 sigmoid 激活功能。回归分支输出无非线性的 6 通道特征图。
在两个分支之间共享权重的层数存在权衡。一方面,我们希望更有效地利用权重。另一方面,由于它们是不同的子任务,我们希望它们更加独立和专业化。
我们将每个对象参数化为定向边界框 b,即 {θ, x~c~, y~c~, w, l},每个元素对应于航向角度(在 [−π, π] 范围内)、对象的中心位置和对象的大小。
与基于长方体的 3D 目标检测相比,我们省略了沿 Z 轴的位置和大小,因为在自动驾驶等应用中,感兴趣的对象被限制在同一接地平面上,因此我们只关心如何在该平面上定位它(此设置在一些文献中也称为 3D 定位 )。
请注意,航向角度被分解为两个相关值,以强制执行角度范围约束。学习目标是 {cos(θ),sin(θ),dx, dy,log(w), log(l)},在训练集上预先归一化为零均值和单位方差。
数据集
KITTI
我们利用我们的自动驾驶平台Anniway开发了具有挑战性的新型现实世界计算机视觉基准。我们感兴趣的任务是:立体、光流、视觉里程计、三维物体检测和三维跟踪。为此,我们为一辆标准旅行车配备了两台高分辨率彩色和灰度摄像机。Velodyne激光扫描仪和GPS定位系统提供了准确的地面实况。我们的数据集是通过在中型城市卡尔斯鲁厄、农村地区和高速公路上行驶来获取的。每张图片最多可看到15辆汽车和30名行人。除了以原始格式提供所有数据外,我们还为每个任务提取基准。对于我们的每个基准,我们还提供了一个评估指标和这个评估网站。初步实验表明,在Middlebury等既定基准上排名靠前的方法在从实验室转移到现实世界时,表现低于平均水平。我们的目标是减少这种偏见,并通过向社区提供具有新困难的现实世界基准来补充现有基准。
nuScenes
nuScenes数据集(发音为/nuõsiõnz/)是Motional(前身为nuTonomy)团队开发的一个用于自动驾驶的公共大规模数据集。Motional正在使无人驾驶汽车成为一种安全、可靠和可访问的现实。通过向公众发布我们的一部分数据,Motional旨在支持公众对计算机视觉和自动驾驶的研究。
为此,收集了波士顿和新加坡的1000个驾驶场景,这两个城市以交通密集和极具挑战性的驾驶环境而闻名。20秒长的场景是手动选择的,以展示一组多样而有趣的驾驶动作、交通状况和意外行为。nuScenes的丰富复杂性将鼓励开发能够在每个场景有几十个物体的城市地区安全驾驶的方法。收集不同大陆的数据进一步使我们能够研究计算机视觉算法在不同地点、天气条件、车辆类型、植被、道路标记以及左右交通中的通用性。
所有检测结果均按照平均精度 (mAP)、平均平移误差 (mATE)、平均比例误差 (mASE)、平均方向误差 (mAOE)、平均速度误差 (AVE)、平均属性误差 (AAE) 和 nuScenes 检测得分 (NDS) 进行评估。
The Waymo opendataset
机器学习领域正在迅速变化。Waymo通过创建和共享一些最大、最多样化的自动驾驶数据集,在为研究界做出贡献方面处于独特的地位。查看我们最新发布的感知对象资产数据集,其中包括31k个具有传感器数据的独特感知对象实例,用于生成建模!
从多传感器数据中提取感知对象:所有5个摄像头和顶级激光雷达 激光雷达特征包括支持三维物体形状重建的三维点云序列。
我们还通过点云形状注册为车辆类别中的所有对象提供了精细的长方体姿态 相机功能包括most_visible_Camera的相机补丁序列、相应相机上投影的激光雷达返回、每个像素的相机光线信息,以及支持对象NeRF重建的自动标记2D全景分割,本文对此进行了详细介绍 来自31K个独特对象实例的120万个对象帧,涵盖2类(车辆和行人)
2030个片段,每个片段20秒,在不同的地理位置和条件下以10Hz(390000帧)采集,1个中距离激光雷达4个短程激光雷达5个摄像头(正面和侧面)同步激光雷达和相机数据激光雷达到摄像机的投影传感器校准和车辆姿态
学习资料
- 3D Object Detection | Papers With Code
- patrick-llgc/Learning-Deep-Learning: Paper reading notes on Deep Learning and Machine Learning (github.com)
- 3D Object Detection Overview | Stereolabs
- 系列二:3D Detection目标检测系列论文总结(2023年更) - 知乎 (zhihu.com)
- 3D点云HuangCongQing/3D-Point-Clouds: 🔥3D点云目标检测&语义分割(深度学习)-SOTA方法,代码,论文,数据集等 (github.com)
