主要是因为Python库的设计很不错,通过这门语言进一步学习并行,涉及到进程线程以及异步编程等.建议是对性能有要求的利用其他语言实现,但是基本的思想、方法是一样的.
创建进程&&线程
- 进程可以包含多个并行运行的线程。
- 通常,操作系统创建和管理线程比进程更能节省CPU的资源。线程用于一些小任务,进程用于繁重的任务——运行应用程序。
- 同一个进程下的线程共享地址空间和其他资源,进程之间相互独立
进程有自己的地址空间,数据栈和其他的辅助数据来追踪执行过程;系统会管理所有进程的执行,通过调度程序来分配计算资源等。1
2
3
4
5
6
7
8
9
10
11
12## The following modules must be imported
import os
import sys
## this is the code to execute
program = "python"
print("Process calling")
arguments = ["called_Process.py"]
## we call the called_Process.py script
os.execvp(program, (program,) + tuple(arguments))
print("Good Bye!!")1
2
3print("Hello Python Parallel Cookbook!!")
closeInput = input("Press ENTER to exit")
print"Closing calledProcess"
线程创建1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37# To use threads you need import Thread using the following code:
from threading import Thread
# Also we use the sleep function to make the thread "sleep"
from time import sleep
# To create a thread in Python you'll want to make your class work as a thread.
# For this, you should subclass your class from the Thread class
class CookBook(Thread):
def __init__(self):
Thread.__init__(self)
self.message = "Hello Parallel Python CookBook!!\n"
# this method prints only the message
def print_message(self):
print(self.message)
# The run method prints ten times the message
def run(self):
print("Thread Starting\n")
x = 0
while (x < 10):
self.print_message()
sleep(2)
x += 1
print("Thread Ended\n")
# start the main process
print("Process Started")
# create an instance of the HelloWorld class
hello_Python = CookBook()
# print the message...starting the thread
hello_Python.start()
# end the main process
print("Process Ended")
Python解释器并不完全是线程安全的。为了支持多线程的Python程序,CPython使用了一个叫做全局解释器锁(Global Interpreter Lock, GIL)的技术。这意味着同一时间只有一个线程可以执行Python代码;执行某一个线程一小段时间之后,Python会自动切换到下一个线程。GIL并没有完全解决线程安全的问题,如果多个线程试图使用共享数据,还是可能导致未确定的行为。
线程的并行
在软件应用中使用最广泛的并发编程范例是多线程。通常,一个应用有一个进程,分成多个独立的线程,并行运行、互相配合,执行不同类型的任务。
线程是独立的处理流程,可以和系统的其他线程并行或并发地执行。多线程可以共享数据和资源,利用所谓的共享内存空间。线程和进程的具体实现取决于你要运行的操作系统,但是总体来讲,我们可以说线程是包含在进程中的,同一进程的多个不同的线程可以共享相同的资源。相比而言,进程之间不会共享资源。
每一个线程基本上包含3个元素:程序计数器,寄存器和栈。与同一进程的其他线程共享的资源基本上包括数据和系统资源。每一个线程也有自己的运行状态,可以和其他线程同步,这点和进程一样。线程的状态大体上可以分为ready,running,blocked。线程的典型应用是应用软件的并行化——为了充分利用现代的多核处理器,使每个核心可以运行单个线程。相比于进程,使用线程的优势主要是性能。相比之下,在进程之间切换上下文要比在统一进程的多线程之间切换上下文要重的多。
多线程编程一般使用共享内容空间进行线程间的通讯。这就使管理内容空间成为多线程编程的重点和难点。
使用Python的threading模块管理多线程.
线程被创建之后并不会马上运行,需要手动调用 start() , join() 让调用它的线程一直等待直到执行结束1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import threading
import time
def func(i):
print("function called by thread %i" % i)
return
def slowProcess():
time.sleep(3)
print("slow process done")
t = threading.Thread(target=slowProcess, args=())
t.start()
t.join()
t = threading.Thread(target=func, args=(1,))
t.start()
print("process quit")
设置t = threading.Thread(target=slowProcess, args=(),name="slowp")线程名称
线程被创建之后并不会马上运行,需要手动调用 start().此外join() 让调用它的线程一直等待直到执行结束(即阻塞调用它的主线程, t 线程执行结束,主线程才会继续执行)
threading.current_thread().name访问执行当前代码的线程的名称.
主线程是MainThread. 实现多线程可以选择继承threading.Thread类或者直接使用threading.Thread方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31exitFlag = 0
class myThread(threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print("starting " + self.name)
print_time(self.name, self.counter, 5)
print("exiting " + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
_thread.exit()
time.sleep(delay)
print("%s:%s" % (threadName, time.ctime(time.time())))
counter -= 1
thread1 = myThread(1, "thread-1", 1)
thread2 = myThread(2, "thread-2", 2)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
threading 模块是创建和管理线程的首选形式。每一个线程都通过一个继承 Thread 类,重写 run() 方法来实现逻辑,这个方法是线程的入口。在主程序中,我们创建了多个 myThread 的类型实例,然后执行 start() 方法启动它们。调用 Thread.__init__ 构造器方法是必须的,通过它我们可以给线程定义一些名字或分组之类的属性。调用 start() 之后线程变为活跃状态,并且持续直到 run() 结束,或者中间出现异常。所有的线程都执行完成之后,程序结束。
线程的同步
当两个或以上对共享内存的操作发生在并发线程中,并且至少有一个可以改变数据,又没有同步机制的条件下,就会产生竞争条件,可能会导致执行无效代码、bug、或异常行为。
Lock锁同步
竞争条件最简单的解决方法是使用锁。锁的操作非常简单,当一个线程需要访问部分共享内存时,它必须先获得锁才能访问。此线程对这部分共享资源使用完成之后,该线程必须释放锁,然后其他线程就可以拿到这个锁并访问这部分资源了。
使用lock同步线程,通过它我们可以将共享资源某一时刻的访问限制在单一线程或单一类型的线程上,线程必须得到锁才能使用资源,并且之后必须允许其他线程使用相同的资源。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50import threading
shared_resource_with_lock = 0
shared_resource_with_no_lock = 0
COUNT = 1000000
shared_resource_lock = threading.Lock()
def increment_with_lock():
global shared_resource_with_lock
for i in range(COUNT):
shared_resource_lock.acquire()
shared_resource_with_lock += 1
shared_resource_lock.release()
def decrement_with_lock():
global shared_resource_with_lock
for i in range(COUNT):
shared_resource_lock.acquire()
shared_resource_with_lock -=1
shared_resource_lock.release()
def increment_without_lock():
global shared_resource_with_no_lock
for i in range(COUNT):
shared_resource_with_no_lock +=1
def decrement_without_lock():
global shared_resource_with_no_lock
for i in range(COUNT):
shared_resource_with_no_lock -=1
if __name__ == "__main__":
t1 = threading.Thread(target=increment_with_lock)
t2 = threading.Thread(target=decrement_with_lock)
t3 = threading.Thread(target=increment_without_lock)
t4 = threading.Thread(target=decrement_without_lock)
t1.start()
t2.start()
t3.start()
t4.start()
t1.join()
t2.join()
t3.join()
t4.join()
print("the value of shared variable with lock management is %s" % shared_resource_with_lock)
print("the value of shared variable with race condition is %s" % shared_resource_with_no_lock)
- 锁有两种状态: locked(被某一线程拿到)和unlocked(可用状态)
我们有两个方法来操作锁:
acquire()和release()如果状态是unlocked, 可以调用
acquire()将状态改为locked- 如果状态是locked,
acquire()会被block直到另一线程调用release()释放锁 - 如果状态是unlocked, 调用
release()将导致RuntimError异常 - 如果状态是locked, 可以调用
release()将状态改为unlocked
尽管理论上行得通,但是锁的策略不仅会导致有害的僵持局面。还会对应用程序的其他方面产生负面影响。这是一种保守的方法,经常会引起不必要的开销,也会限制程序的可扩展性和可读性。更重要的是,有时候需要对多进程共享的内存分配优先级,使用锁可能和这种优先级冲突。最后,从实践的经验来看,使用锁的应用将对debug带来不小的麻烦。所以,最好使用其他可选的方法确保同步读取共享内存,避免竞争条件。
事实上我执行这段代码时跟线程是否join有关,基本上上面代码是否加锁都没有出问题
RLock锁同步
如果你想让只有拿到锁的线程才能释放该锁,那么应该使用 RLock() 对象。和 Lock() 对象一样, RLock() 对象有两个方法: acquire() 和 release() 。当你需要在类外面保证线程安全,又要在类内使用同样方法的时候 RLock() 就很实用了
RLock其实叫做“Reentrant Lock”,就是可以重复进入的锁,也叫做“递归锁”。这种锁对比Lock有是三个特点:1. 谁拿到谁释放。如果线程A拿到锁,线程B无法释放这个锁,只有A可以释放;2. 同一线程可以多次拿到该锁,即可以acquire多次;3. acquire多少次就必须release多少次,只有最后一次release才能改变RLock的状态为unlocked
1 | import threading |
相比于Lock有一些更稳定的设定.
信号量同步
信号量是一个内部数据,用于标明当前的共享资源可以有多少并发读取。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29import threading
import time
import random
semaphore = threading.Semaphore(0)
def consumer():
print("consumer is waiting.")
semaphore.acquire()
print("consumer notify: consumed item number %s " % item)
def producer():
global item
time.sleep(10)
item = random.randint(0, 1000)
print("producer notify:produced item number %s" % item)
semaphore.release()
if __name__ == '__main__':
for i in range(0,5):
t1 = threading.Thread(target=producer)
t2 = threading.Thread(target=consumer)
t1.start()
t2.start()
t1.join()
t2.join()
print("program terminated")
信号量的一个特殊用法是互斥量。互斥量是初始值为1的信号量,可以实现数据、资源的互斥访问。
信号量在支持多线程的编程语言中依然应用很广,然而这可能导致死锁的情况。例如,现在有一个线程t1先等待信号量s1,然后等待信号量s2,而线程t2会先等待信号量s2,然后再等待信号量s1,这样就可能会发生死锁,导致t1等待s2,但是t2在等待s1。
条件进行同步
条件指的是应用程序状态的改变。这是另一种同步机制,其中某些线程在等待某一条件发生,其他的线程会在该条件发生的时候进行通知。一旦条件发生,线程会拿到共享资源的唯一权限1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60from threading import Thread, Condition
import time
items = []
condition = Condition()
class consumer(Thread):
def __init__(self):
Thread.__init__(self)
def consume(self):
global condition
global items
condition.acquire()
if len(items) == 0:
condition.wait()
print("consumer notify: no item to consume")
items.pop()
print("consumer notify: consumed 1 item")
print("consumer notify: items to consume are " + str(len(items)))
def run(self):
for i in range(0, 20):
time.sleep(10)
self.consume()
class producer(Thread):
def __init__(self):
Thread.__init__(self)
def produce(self):
global condition
global items
condition.acquire()
if len(items) == 10:
condition.wait()
print("Producer notify : items producted are " + str(len(items)))
print("Producer notify : stop the production!!")
items.append(1)
print("Producer notify : total items producted " + str(len(items)))
condition.notify()
condition.release()
def run(self):
for i in range(0, 20):
time.sleep(1)
self.produce()
if __name__ == "__main__":
producer = producer()
consumer = consumer()
producer.start()
consumer.start()
producer.join()
consumer.join()
事件同步
1 | import time |
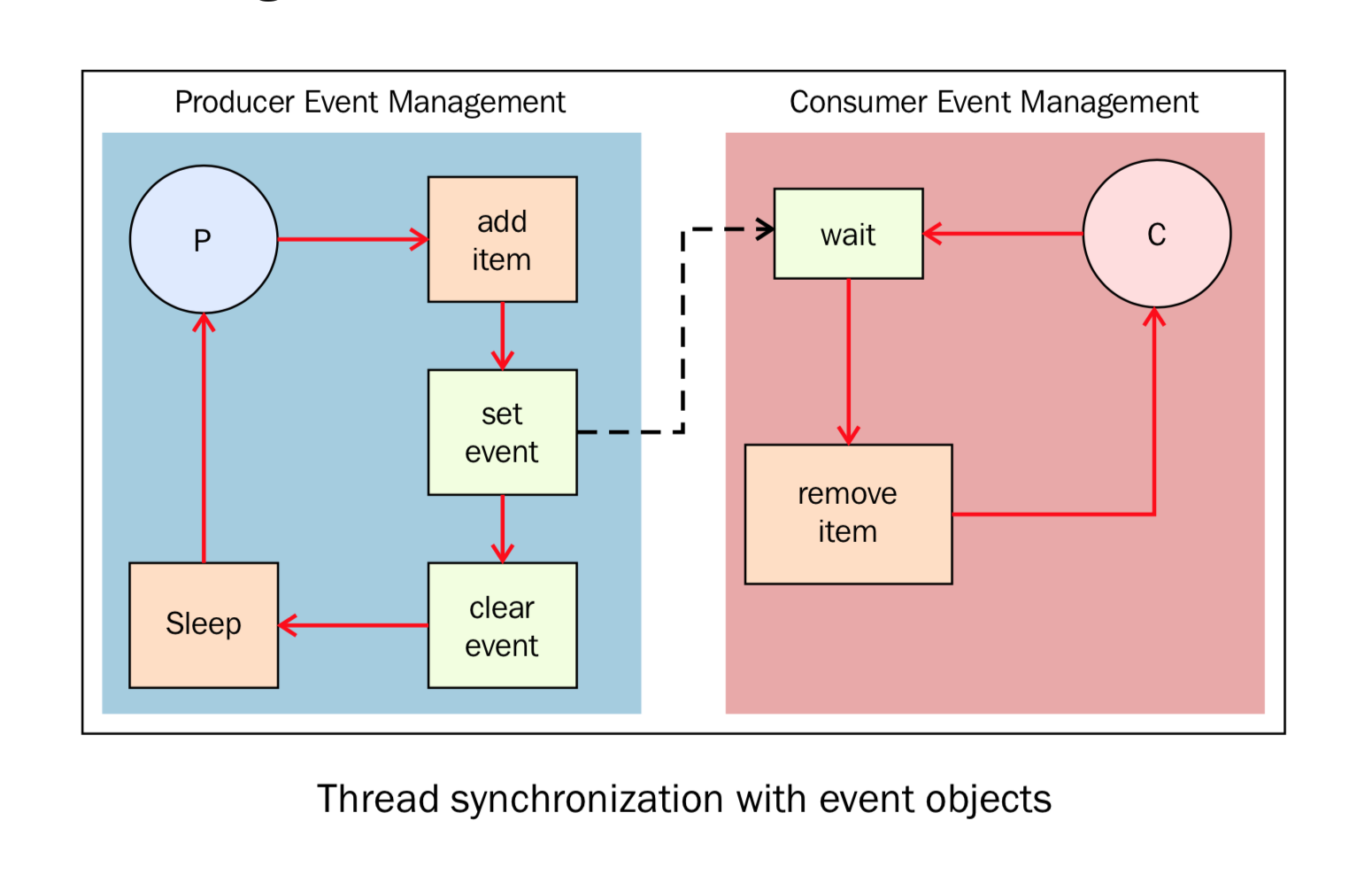
使用with简化
1 | import threading |
此外,当线程之间共享资源时,可以利用上面的原语,也可以使用queue.队列操作起来更容易,也使多线程编程更安全,因为队列可以将资源的使用通过单线程进行完全控制,并且允许使用更加整洁和可读性更高的设计模式。
Queue常用的方法有以下四个:
put(): 往queue中放一个itemget(): 从queue删除一个item,并返回删除的这个itemtask_done(): 每次item被处理的时候需要调用这个方法join(): 所有item都被处理之前一直阻塞
进程的并行
由父进程创建子进程。父进程既可以在产生子进程之后继续异步执行,也可以暂停等待子进程创建完成之后再继续执行.1
2
3
4
5
6
7
8
9
10
11
12
13import multiprocessing
def foo(i):
print('called function in process:%s' % i)
return
if __name__ == '__main__':
Process_jobs = []
for i in range(5):
p = multiprocessing.Process(target=foo, args=(i,))
Process_jobs.append(p)
p.start()
p.join()
使用进程对象调用 join() 方法。如果没有 join() ,主进程退出之后子进程会留在idle中,必须手动杀死它们。
进程名字与获取与线程类似.
后台运行进程
如果需要处理比较巨大的任务,又不需要人为干预,将其作为后台进程执行是个非常常用的编程模型。此进程又可以和其他进程并发执行。通过Python的multiprocessing模块的后台进程选项,我们可以让进程在后台运行
1 | import multiprocessing |
为了在后台运行进程,我们设置 daemon 参数为 True
在非后台运行的进程会看到一个输出,后台运行的没有输出,后台运行进程在主进程结束之后会自动结束
注意,后台进程不允许创建子进程。否则,当后台进程跟随父进程退出的时候,子进程会变成孤儿进程。另外,它们并不是Unix的守护进程或服务(daemons or services),所以当非后台进程退出,它们会被终结。
1 | import threading |
杀掉进程
可以使用 terminate() 方法立即杀死一个进程。另外,我们可以使用 is_alive() 方法来判断一个进程是否还存活。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import multiprocessing
import time
def foo():
print("Starting function")
time.sleep(0.1)
print("Finished function")
if __name__ == '__main__':
p = multiprocessing.Process(target=foo)
print('Process before execution:', p, p.is_alive())
p.start()
print('Process running:', p, p.is_alive())
p.terminate()
print('Process terminated:', p, p.is_alive())
p.join()
print('Process joined:', p, p.is_alive())
print('Process exit code:', p.exitcode)
进程的 ExitCode 状态码(status code)验证进程已经结束, ExitCode 可能的值如下:
- == 0: 没有错误正常退出
- > 0: 进程有错误,并以此状态码退出
- < 0: 进程被
-1 *的信号杀死并以此作为 ExitCode 退出
子类中使用进程
实现一个自定义的进程子类,需要以下三步:
- 定义
Process的子类 - 覆盖
__init__(self [,args])方法来添加额外的参数 - 覆盖
run(self, [.args])方法来实现Process启动的时候执行的任务
创建 Porcess 子类之后,你可以创建它的实例并通过 start() 方法启动它,启动之后会运行 run() 方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# -*- coding: utf-8 -*-
# 自定义子类进程
import multiprocessing
import timeit
class MyProcess(multiprocessing.Process):
def run(self):
print ('called run method in process: %s' % self.name)
return
if __name__ == '__main__':
timestart = timeit.default_timer()
jobs = []
for i in range(5):
p = MyProcess()
jobs.append(p)
p.start()
p.join()
print('Time elapsed:', (timeit.default_timer() - timestart))
join() 命令可以让主进程等待其他进程结束最后退出。
进程中交换对象
并行应用常常需要在进程之间交换数据。Multiprocessing库有两个Communication Channel可以交换对象:队列(queue)和管道(pipe)
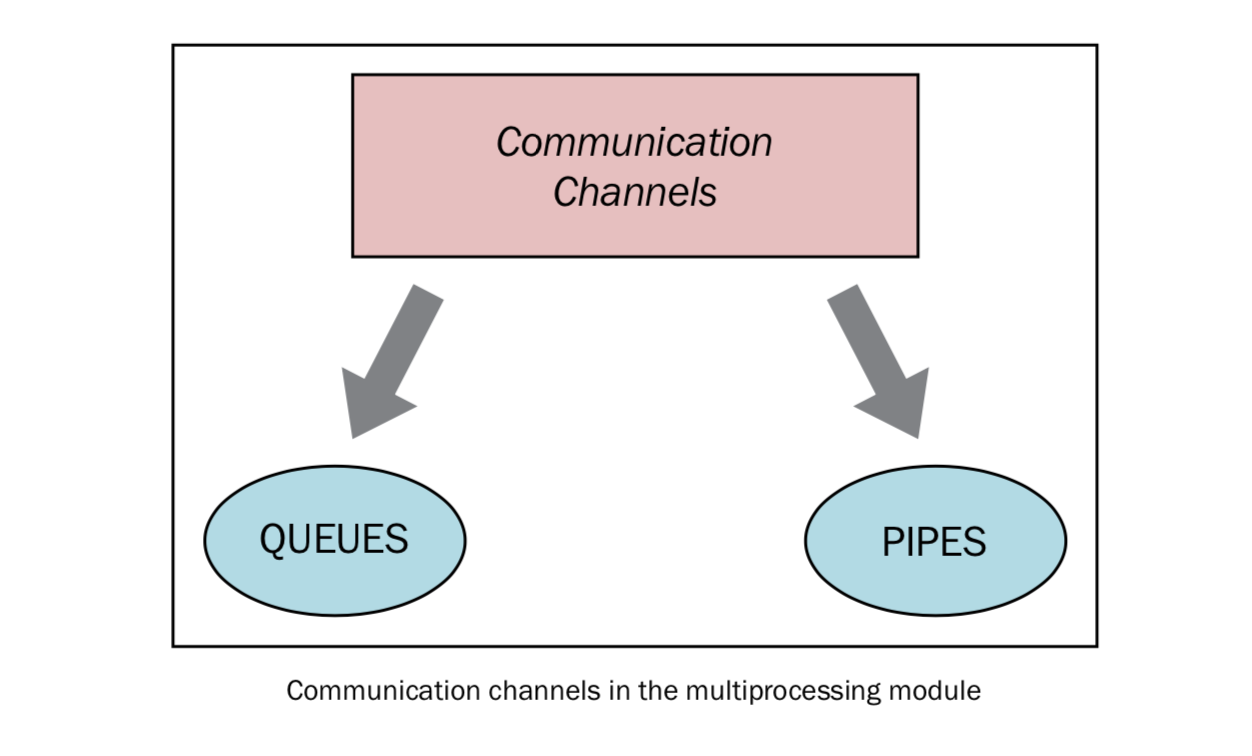
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41import multiprocessing
import random
import time
class Producer(multiprocessing.Process):
def __init__(self, queue):
multiprocessing.Process.__init__(self)
self.queue = queue
def run(self):
for i in range(10):
item = random.randint(0, 256)
self.queue.put(item)
print("Process Producer : item %d appended to queue %s" % (item, self.name))
time.sleep(1)
print("The size of queue is %s" % self.queue.qsize())
class Consumer(multiprocessing.Process):
def __init__(self, queue):
multiprocessing.Process.__init__(self)
self.queue = queue
def run(self):
while True:
if self.queue.empty():
print("the queue is empty")
break
else:
time.sleep(2)
item = self.queue.get()
print('Process Consumer : item %d popped from by %s \n' % (item, self.name))
time.sleep(1)
if __name__ == '__main__':
queue = multiprocessing.Queue()
process_producer = Producer(queue)
process_consumer = Consumer(queue)
process_producer.start()
process_consumer.start()
process_producer.join()
process_consumer.join()
队列还有一个 JoinableQueue 子类,它有以下两个额外的方法:
task_done(): 此方法意味着之前入队的一个任务已经完成,比如,get()方法从队列取回item之后调用。所以此方法只能被队列的消费者调用。join(): 此方法将进程阻塞,直到队列中的item全部被取出并执行。
此外还可以通过Pipe交换对象.
进程同步
多个进程可以协同工作来完成一项任务。通常需要共享数据。所以在多进程之间保持数据的一致性就很重要了。需要共享数据协同的进程必须以适当的策略来读写数据。相关的同步原语和线程的库很类似。
进程的同步原语如下:
- Lock: 这个对象可以有两种装填:锁住的(locked)和没锁住的(unlocked)。一个Lock对象有两个方法,
acquire()和release(),来控制共享数据的读写权限。 - Event: 实现了进程间的简单通讯,一个进程发事件的信号,另一个进程等待事件的信号。
Event对象有两个方法,set()和clear(),来管理自己内部的变量。 - Condition: 此对象用来同步部分工作流程,在并行的进程中,有两个基本的方法:
wait()用来等待进程,notify_all()用来通知所有等待此条件的进程。 - Semaphore: 用来共享资源,例如,支持固定数量的共享连接。
- Rlock: 递归锁对象。其用途和方法同
Threading模块一样。 - Barrier: 将程序分成几个阶段,适用于有些进程必须在某些特定进程之后执行。处于障碍(Barrier)之后的代码不能同处于障碍之前的代码并行。
1 | import multiprocessing |
进程之间管理状态
Python的多进程模块提供了在所有的用户间管理共享信息的管理者(Manager)。一个管理者对象控制着持有Python对象的服务进程,并允许其它进程操作共享对象。
管理者有以下特性:
- 它控制着管理共享对象的服务进程
- 它确保当某一进程修改了共享对象之后,所有的进程拿到额共享对象都得到了更新
1 | import multiprocessing |
使用进程池
多进程库提供了 Pool 类来实现简单的多进程任务。 Pool 类有以下方法:
apply(): 直到得到结果之前一直阻塞。apply_async(): 这是apply()方法的一个变体,返回的是一个result对象。这是一个异步的操作,在所有的子类执行之前不会锁住主进程。map(): 这是内置的map()函数的并行版本。在得到结果之前一直阻塞,此方法将可迭代的数据的每一个元素作为进程池的一个任务来执行。map_async(): 这是map()方法的一个变体,返回一个result对象。如果指定了回调函数,回调函数应该是callable的,并且只接受一个参数。当result准备好时会自动调用回调函数(除非调用失败)。回调函数应该立即完成,否则,持有result的进程将被阻塞。
1 | import multiprocessing |
异步编程
concurrent.futures
concurrent.futures 模块,这个模块具有线程池和进程池、管理并行编程任务、处理非确定性的执行流程、进程/线程同步等功能。
此模块由以下部分组成:
concurrent.futures.Executor: 这是一个虚拟基类,提供了异步执行的方法。submit(function, argument): 调度函数(可调用的对象)的执行,将argument作为参数传入。map(function, argument): 将argument作为参数执行函数,以 异步 的方式。shutdown(Wait=True): 发出让执行者释放所有资源的信号。concurrent.futures.Future: 其中包括函数的异步执行。Future对象是submit任务(即带有参数的functions)到executor的实例。
Executor是抽象类,可以通过子类访问,即线程或进程的 ExecutorPools 。因为,线程或进程的实例是依赖于资源的任务,所以最好以“池”的形式将他们组织在一起,作为可以重用的launcher或executor。
线程池或进程池是用于在程序中优化和简化线程/进程的使用。通过池,你可以提交任务给executor。池由两部分组成,一部分是内部的队列,存放着待执行的任务;另一部分是一系列的进程或线程,用于执行这些任务。池的概念主要目的是为了重用:让线程或进程在生命周期内可以多次使用。它减少了创建创建线程和进程的开销,提高了程序性能。重用不是必须的规则,但它是程序员在应用中使用池的主要原因。
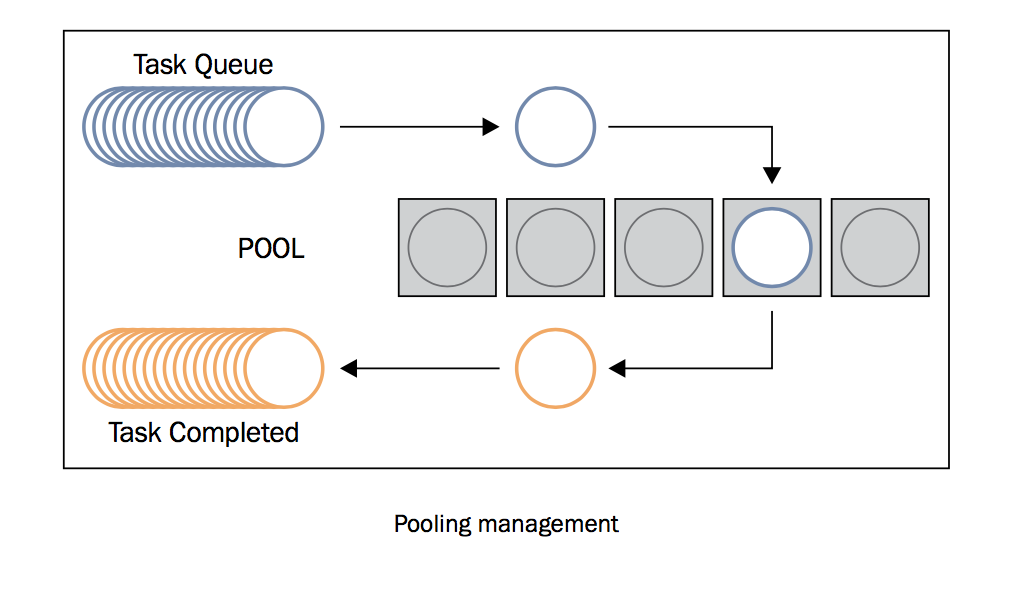
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35import concurrent.futures
import time
number_list = [i for i in range(10)]
def evaluate_item(x):
result_item = count(x)
return result_item
def count(number):
for i in range(0, 10000000):
i += 1
return i * number
if __name__ == '__main__':
start_time = time.time()
for item in number_list:
print(evaluate_item(item))
print("Sequential execution in " + str(time.time() - start_time), "seconds")
start_time_1 = time.time()
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(evaluate_item, item) for item in number_list]
for future in concurrent.futures.as_completed(futures):
print(future.result())
print("Thread pool execution in " + str(time.time() - start_time_1), "seconds")
start_time_2 = time.time()
with concurrent.futures.ProcessPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(evaluate_item, item) for item in number_list]
for future in concurrent.futures.as_completed(futures):
print(future.result())
print("Process pool execution in " + str(time.time() - start_time_2), "seconds")1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import concurrent.futures
# 定义一个计算平方的函数
def square(x):
return x * x
# 创建一个ThreadPoolExecutor对象,设置线程池中的线程数量为2
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
# 提交任务给线程池,并获取Future对象
future1 = executor.submit(square, 5)
future2 = executor.submit(square, 8)
# 获取任务的执行结果
result1 = future1.result()
result2 = future2.result()
# 打印结果
print(f"Result 1: {result1}")
print(f"Result 2: {result2}")
Asyncio管理事件循环
Python的Asyncio模块提供了管理事件、协程、任务和线程的方法,以及编写并发代码的原语。此模块的主要组件和概念包括:
- 事件循环: 在Asyncio模块中,每一个进程都有一个事件循环。
- 协程: 这是子程序的泛化概念。协程可以在执行期间暂停,这样就可以等待外部的处理(例如IO)完成之后,从之前暂停的地方恢复执行。
- Futures: 定义了
Future对象,和concurrent.futures模块一样,表示尚未完成的计算。 - Tasks: 这是Asyncio的子类,用于封装和管理并行模式下的协程。
1 | while (1) { |
可以产生事件的实体叫做事件源,能处理事件的实体叫做事件处理者。此外,还有一些第三方实体叫做事件循环。它的作用是管理所有的事件,在整个程序运行过程中不断循环执行,追踪事件发生的顺序将它们放到队列中,当主线程空闲的时候,调用相应的事件处理者处理事件。
Asyncio提供了一下方法来管理事件循环:
loop = get_event_loop(): 得到当前上下文的事件循环。loop.call_later(time_delay, callback, argument): 延后time_delay秒再执行callback方法。loop.call_soon(callback, argument): 尽可能快调用callback,call_soon()函数结束,主线程回到事件循环之后就会马上调用callback。loop.time(): 以float类型返回当前时间循环的内部时间。asyncio.set_event_loop(): 为当前上下文设置事件循环。asyncio.new_event_loop(): 根据此策略创建一个新的时间循环并返回。loop.run_forever(): 在调用stop()之前将一直运行。
1 | import asyncio |
Asyncio管理协程
子程序不能单独执行,只能在主程序的请求下执行,主程序负责协调使用各个子程序。协程就是子程序的泛化。和子程序一样的事,协程只负责计算任务的一步
和子程序不一样的是,协程没有主程序来进行调度。这是因为协程通过管道连接在一起,没有监视函数负责顺序调用它们。在协程中,执行点可以被挂起,可以被从之前挂起的点恢复执行。通过协程池就可以插入到计算中:运行第一个任务,直到它返回(yield)执行权,然后运行下一个,这样顺着执行下去。
协程的另外一些重要特性如下:
- 协程可以有多个入口点,并可以yield多次
- 协程可以将执行权交给其他协程
yield表示协程在此暂停,并且将执行权交给其他协程。因为协程可以将值与控制权一起传递给另一个协程,所以“yield一个值”就表示将值传给下一个执行的协程1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60import asyncio
import time
from random import randint
async def StartState():
print("Start State called \n")
input_value = randint(0, 1)
if input_value == 0:
result = await State2(input_value)
else:
result = await State1(input_value)
print("Resume of the Transition : \nStart State calling " + result)
async def State2(transition_value):
outputValue = str("State 2 with transition value = %s \n" % transition_value)
input_value = randint(0, 1)
print("...Evaluating...")
if (input_value == 0):
result = await State1(input_value)
else:
result = await State3(input_value)
return outputValue + str(result)
async def EndState(transition_value):
outputValue = str("End State with transition value = %s \n" % transition_value)
print("...Stop Computation...")
return outputValue
async def State3(transition_value):
outputValue = str("State 3 with transition value = %s \n" % transition_value)
input_value = randint(0, 1)
print("...Evaluating...")
if input_value == 0:
result = await State1(input_value)
else:
result = await EndState(input_value)
return outputValue + str(result)
async def State1(transition_value):
outputValue = str("State 1 with transition value = " + str(transition_value) + " \n")
input_value = randint(0, 1)
await asyncio.sleep(1)
print('...Evaluating...')
if input_value == 0:
result = await State3(input_value)
else:
result = await State2(input_value)
result = "State 1 calling " + result
return outputValue + str(result)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(StartState())
loop.close()
object async_generator can't be used in 'await' expression async函数中如果使用了yield相当于async_generator,后者中不能使用await.
Asyncio控制任务
Asyncio是用来处理事件循环中的异步进程和并发任务执行的。它还提供了
asyncio.Task()类,可以在任务中使用协程。它的作用是,在同一事件循环中,运行某一个任务的同时可以并发地运行多个任务。当协程被包在任务中,它会自动将任务和事件循环连接起来,当事件循环启动的时候,任务自动运行。这样就提供了一个可以自动驱动协程的机制。
asyncio.Task(coroutine) 方法来处理计算任务,它可以调度协程的执行。任务对协程对象在事件循环的执行负责。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import asyncio
async def factorial(number):
f = 1
for i in range(2, number + 1):
print("Asyncio.Task: Compute factorial(%s)" % (i))
await asyncio.sleep(1)
f *= i
print("Asyncio.Task: factorial(%s) = %s" % (number, f))
async def fibonacci(number):
a,b = 0,1
for i in range(number):
print("Asyncio.Task: Compute fibonacci(%s)" % (i))
await asyncio.sleep(1)
a,b = b, a + b
print("Asyncio.Task: fibonacci(%s) = %s" % (number, a))
if __name__ == '__main__':
tasks = [asyncio.Task(factorial(10)), asyncio.Task(fibonacci(10))]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
使用asyncio和futures
Asyncio 模块的另一个重要的组件是
Future类。它和concurrent.futures.Futures很像,但是针对Asyncio的事件循环做了很多定制。asyncio.Futures类代表还未完成的结果(有可能是一个Exception)。所以综合来说,它是一种抽象,代表还没有做完的事情。
cancel(): 取消future的执行,调度回调函数result(): 返回future代表的结果exception(): 返回future中的Exceptionadd_done_callback(fn): 添加一个回调函数,当future执行的时候会调用这个回调函数remove_done_callback(fn): 从“call whten done”列表中移除所有callback的实例set_result(result): 将future标为执行完成,并且设置result的值set_exception(exception): 将future标为执行完成,并设置Exception
类似于js的Promise?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38import asyncio
future = asyncio.Future
from random import randint
import sys
async def first_coroutine(future, N):
count = 0
for i in range(1, N + 1):
count += i
await asyncio.sleep(3)
future.set_result("First coroutine total count: " + str(count))
async def second_coroutine(future, N):
count = 1
for i in range(2, N + 1):
count *= i
await asyncio.sleep(2)
future.set_result("Second coroutine total count: " + str(count))
def got_result(future):
print(future.result())
if __name__ == '__main__':
N = int(sys.argv[1])
future1 = asyncio.Future()
future2 = asyncio.Future()
tasks = [
first_coroutine(future1, N),
second_coroutine(future2, N)
]
future1.add_done_callback(got_result)
future2.add_done_callback(got_result)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
参考资料
- 1. 介绍 — python-parallel-programming-cookbook-cn 1.0 文档 (python-parallel-programmning-cookbook.readthedocs.io)
- [Python 多线程] 详解daemon属性值None,False,True的区别_daemon=true-CSDN博客
- Python 异步编程入门 - 阮一峰的网络日志 (ruanyifeng.com)
- 介绍 Python 线程及其实现 (freecodecamp.org)
- A minimalistic guide for understanding asyncio in Python | by Naren Yellavula | Dev bits | Medium
- Getting Started with Asyncio in Python | TutorialEdge.net
