1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
| import time
from tkinter.ttk import *
import tkinter as tk
from tkinter import *
import requests
from tkinter import messagebox
from lxml import etree
import os
import os.path
import threading
from PIL import Image, ImageTk
class Application(tk.Frame):
def __init__(self, master=None):
super().__init__(master)
self.button = tk.Button(self, text="确定", )
self.entry = tk.Entry(self, font="times 15")
self.endbtn = Button(self, text="结束", command=stop)
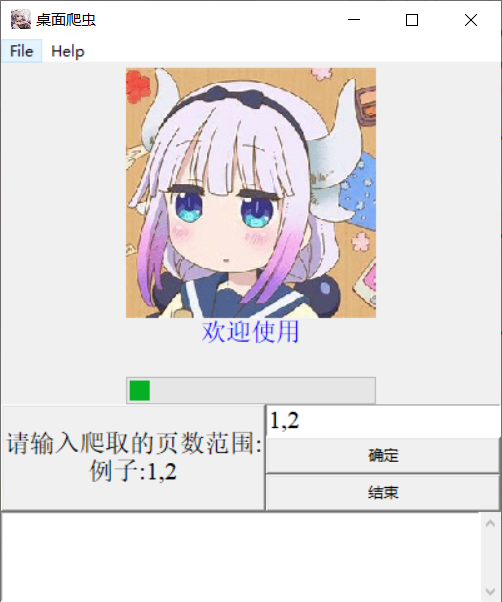
self.label1 = tk.Label(self, text="请输入爬取的页数范围:\n例子:1,2", font="times 15", relief="raised")
self.create_widget()
self.pack()
def create_widget(self):
self.entry.insert(0, "1,2")
self.label1.pack(side=LEFT, fill=BOTH)
self.entry.pack(fill=X)
self.button.pack(fill=BOTH)
self.button.bind("<Button-1>", self.get_info)
self.entry.bind("<Return>", self.get_info)
self.endbtn.pack(fill=X)
def get_info(self, event):
entry_info = self.entry.get()
try:
fir_page = int(entry_info.split(",")[0])
sec_page = int(entry_info.split(",")[1])
except IndexError as e:
messagebox.showwarning("提示", "输入格式错误\n%s" % e)
return
except ValueError as e:
messagebox.showwarning("提示", "输入格式错误\n%s" % e)
return
except Exception as e:
messagebox.showwarning("提示", "输入格式错误\n%s" % e)
return
spider = Spider(fir_page, sec_page)
spider.setDaemon(True)
var.set("正在爬取...")
spider.start()
class Spider(threading.Thread):
__headers = {'user_agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.55", "Connection": "close"}
__url = "https://gelbooru.com/index.php?page=post&s=list&tags=all&pid={}"
flag = False
def __init__(self, fir_page, sec_page):
Spider.flag = False
super().__init__(None)
self.fir_page = (fir_page - 1) * 42
self.sec_page = sec_page * 42
self.tag = True
def run(self):
pb.start()
self.parse()
pb.stop()
var.set("爬取完毕")
messagebox.showinfo("提示消息", "爬取结束了")
def parse(self):
text.delete("1.0", END)
requests.adapters.DEFAULT_RETRIES = 5
text.insert(END, "下载至{}\n".format(os.getcwd() + r'\images或\videos'))
for n in range(self.fir_page, self.sec_page + 1):
if Spider.flag:
break
time.sleep(1.5)
try:
res = requests.get(self.__url.format(n), headers=self.__headers)
except requests.exceptions.ConnectionError as e:
messagebox.showinfo("出现问题", "爬取频繁,请连接代理\n%s" % e)
pb.stop()
var.set("爬取完毕")
return
selector = etree.HTML(res.text)
images_urls = selector.xpath("//article//a/@href")
for image_url in images_urls:
if Spider.flag:
break
self.parse_next(image_url)
def parse_next(self, image_url):
image_id = image_url.split("=")[-1]
next_url = image_url
time.sleep(1.5)
res = requests.get(next_url, headers=self.__headers)
selector = etree.HTML(res.text)
try:
img = selector.xpath("//img[@id='image']/@src")[0]
except IndexError:
img = selector.xpath("//video/source[1]/@src")[0]
self.tag = False
self.download(img, image_id)
def download(self, img, image_id):
if Spider.flag:
return
time.sleep(0.5)
suffix = img.split(".")[-1]
res = requests.get(img, headers=self.__headers)
text.insert(END, "正在下载:%s\n" % img)
if self.tag:
if not os.path.exists("./images"):
os.mkdir("./images")
with open('images/{0}.{1}'.format(image_id, suffix), 'wb+') as f:
f.write(res.content)
else:
if not os.path.exists("./videos"):
os.mkdir("./videos")
with open('videos/{0}.{1}'.format(image_id, suffix), 'wb+') as f:
f.write(res.content)
text.insert(END, "下载成功:%s\n" % img)
def stop():
Spider.flag = True
def open_current():
base_path = os.getcwd()
if not os.path.exists("./images"):
is_cre = messagebox.askyesno("提示", "不存在图片文件夹,是否创建?")
if is_cre:
os.mkdir("./images")
path = base_path + r"\images"
else:
path = base_path
else:
path = base_path + r"\images"
os.system("explorer.exe %s" % path)
def show_myinfo():
my_info = """
website:http://sekyoro.top/
github:https://github.com/drowning-in-codes
一起学习
"""
toplevel = Toplevel()
toplevel.title("关于我")
toplevel.iconbitmap("th.ico")
toplevel.geometry("400x350")
info_label = Label(toplevel, font="times 15", text=my_info, image=info_tk_image, compound="top", justify="left")
info_label.pack()
def set_window():
root.title("桌面爬虫")
root.geometry("400x450")
root.iconbitmap("th.ico")
label.pack()
menubar = Menu(root)
filemenu = Menu(menubar, tearoff=0)
menubar.add_cascade(label="File", menu=filemenu)
filemenu.add_command(label="Open", command=open_current)
filemenu.add_separator()
filemenu.add_command(label="Exit", command=root.destroy)
helpmenu = Menu(menubar, tearoff=0)
helpmenu.add_command(label="About me", command=show_myinfo)
menubar.add_cascade(label="Help", menu=helpmenu)
root.config(menu=menubar)
text_label = Label(root, textvariable=var).pack()
if __name__ == "__main__":
root = tk.Tk()
image = Image.open("OIP-C.gif")
image = image.resize((200, 200))
image_tk = ImageTk.PhotoImage(image)
label = tk.Label(root, font="20", fg="blue", text="欢迎使用", image=image_tk, compound="top")
var = StringVar()
set_window()
pb = Progressbar(root, mode="indeterminate", length=200, name="进度")
pb["value"] = 0
pb["maximum"] = 100
pb.pack()
app = Application(root)
info_image = Image.open("info.png")
info_image = info_image.resize((200, 200))
info_tk_image = ImageTk.PhotoImage(info_image)
yscrollbar = Scrollbar(root)
text = Text(root)
yscrollbar.pack(side=RIGHT, fill=Y)
text.pack()
yscrollbar.config(command=text.yview)
text.config(yscrollcommand=yscrollbar.set)
app.mainloop()
|